Global change and the ecology of cities
1
2008
... 土地利用和地表覆盖变化是全球变化研究领域的一个重要方向,其动态也是人类对全球变化的响应核心.地表覆盖作为人类活动与自然要素共同干预与作用的结果,是陆地表层生态系统的重要影响因素[1].因此,诸如地表过程模型、生态系统服务功能等研究中,地表覆盖数据经常作为输入变量,而地表覆盖分类的精度就成为决定研究结果可靠性的重要因素之一[2].尽管目前已经出现大量开放获取的地表覆盖产品,但是对于一些偏远地区,可用的良好精度高分辨率产品缺乏且更新缓慢,同时这些地区还面临全球产品在本地区精度低于平均精度的难题[3].因此,对于单期高质量产品和同源的遥感数据集,高效便捷的地表覆盖自更新方法亟待开发. ...
Implementing large-scale and long-term functional biodiversity research: The Biodiversity Exploratories
1
2010
... 土地利用和地表覆盖变化是全球变化研究领域的一个重要方向,其动态也是人类对全球变化的响应核心.地表覆盖作为人类活动与自然要素共同干预与作用的结果,是陆地表层生态系统的重要影响因素[1].因此,诸如地表过程模型、生态系统服务功能等研究中,地表覆盖数据经常作为输入变量,而地表覆盖分类的精度就成为决定研究结果可靠性的重要因素之一[2].尽管目前已经出现大量开放获取的地表覆盖产品,但是对于一些偏远地区,可用的良好精度高分辨率产品缺乏且更新缓慢,同时这些地区还面临全球产品在本地区精度低于平均精度的难题[3].因此,对于单期高质量产品和同源的遥感数据集,高效便捷的地表覆盖自更新方法亟待开发. ...
Key issues in rigorous accuracy assessment of land cover products
1
2019
... 土地利用和地表覆盖变化是全球变化研究领域的一个重要方向,其动态也是人类对全球变化的响应核心.地表覆盖作为人类活动与自然要素共同干预与作用的结果,是陆地表层生态系统的重要影响因素[1].因此,诸如地表过程模型、生态系统服务功能等研究中,地表覆盖数据经常作为输入变量,而地表覆盖分类的精度就成为决定研究结果可靠性的重要因素之一[2].尽管目前已经出现大量开放获取的地表覆盖产品,但是对于一些偏远地区,可用的良好精度高分辨率产品缺乏且更新缓慢,同时这些地区还面临全球产品在本地区精度低于平均精度的难题[3].因此,对于单期高质量产品和同源的遥感数据集,高效便捷的地表覆盖自更新方法亟待开发. ...
Advances of four machine larning methods for spatial data handling: A review
1
2020
... 在遥感图像处理与地学应用研究中,地表覆盖遥感图像分类是一项重要的工作.通常从是否有标记样本参与模型训练角度,遥感图像分类可以分为监督、半监督、弱监督、非监督等4种类型[4].地表覆盖的监督分类方法发展至今,在输入的特征维度、基本操作单元以及分类器等方面经历了巨大进步[5].但是,无论数据源和分类器如何进步,标记样本的获取仍然是建立健壮分类模型的重要步骤.标记样本的提取不仅是分类精度的重要决定因素,而且对于传统方法而言,由于样本在空间上的分布具有一定的离散性,外业工作在消耗人力与资金的同时,在一定程度上也影响着工期长短.因此,精确样本的快速获取对于缩短地表覆盖分类时间至关重要. ...
高光谱遥感影像分类研究进展
2
2016
... 在遥感图像处理与地学应用研究中,地表覆盖遥感图像分类是一项重要的工作.通常从是否有标记样本参与模型训练角度,遥感图像分类可以分为监督、半监督、弱监督、非监督等4种类型[4].地表覆盖的监督分类方法发展至今,在输入的特征维度、基本操作单元以及分类器等方面经历了巨大进步[5].但是,无论数据源和分类器如何进步,标记样本的获取仍然是建立健壮分类模型的重要步骤.标记样本的提取不仅是分类精度的重要决定因素,而且对于传统方法而言,由于样本在空间上的分布具有一定的离散性,外业工作在消耗人力与资金的同时,在一定程度上也影响着工期长短.因此,精确样本的快速获取对于缩短地表覆盖分类时间至关重要. ...
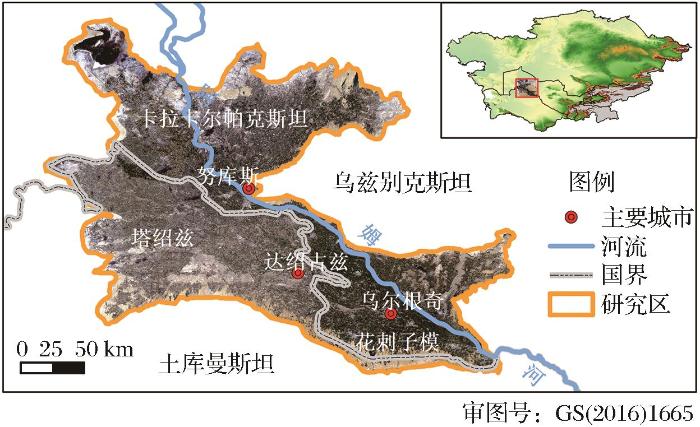
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
高光谱遥感影像分类研究进展
2
2016
... 在遥感图像处理与地学应用研究中,地表覆盖遥感图像分类是一项重要的工作.通常从是否有标记样本参与模型训练角度,遥感图像分类可以分为监督、半监督、弱监督、非监督等4种类型[4].地表覆盖的监督分类方法发展至今,在输入的特征维度、基本操作单元以及分类器等方面经历了巨大进步[5].但是,无论数据源和分类器如何进步,标记样本的获取仍然是建立健壮分类模型的重要步骤.标记样本的提取不仅是分类精度的重要决定因素,而且对于传统方法而言,由于样本在空间上的分布具有一定的离散性,外业工作在消耗人力与资金的同时,在一定程度上也影响着工期长短.因此,精确样本的快速获取对于缩短地表覆盖分类时间至关重要. ...
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
迁移学习支持下的遥感影像对象级分类样本自动选择方法
2
2014
... 样本迁移是近年来流行的一种基于迁移学习(Transfer Learning, TL)的样本提取思想,相比传统方法而言,样本迁移避免了大量外业调查工作,有效地缩短了采样时间,减轻了分类操作人员的工作负担,节省了所需经费.近年来,吴田军和林聪等[6-7]的研究基于迁移学习的思想,通过往期产品向目标影像进行样本的转移,使得采样的工作量和时间大大减少,且在分类结果上具有良好的表现.刘万军等[8]通过迁移学习思想,结合光谱相似度方法,解决了小样本的问题.Pan等[9]在变化向量分析的方法的基础上提出基于对象的扩展变化向量检测方法进行样本的迁移,通过支持向量机(Support Vector Machine, SVM)进行分类,较传统的基于像元的向量变化检测方法分类精度有了明显提升. ...
... 土地资源作为重要自然资源和社会经济资源,具有整体性、位置固定性和生产性等属性,基于这些特性,一定区域的土地表层覆盖随着社会经济发展发生一定变化的同时,存在大量土地的地表覆盖仍然维持其原有状态.而遥感影像分类的基础就在于,相同的地物具有共同的光谱或形态特征.实地采样人工解译没有充分利用未改变的地物光谱特征,降低了分类时效性.假设已有地表覆产品对应时相的遥感影像数据集为,待分类时相的遥感影像数据集为,m为波段数,n为像素数.则存在X的时相到Y的时相,未发生变化耕地、建筑、水域等地物,各类地物光谱分布的统计差异具有鲁棒性,其对应.样本迁移的工作就是在待分类影像中没有发生改变的地物上采集样本,用于对影像进行地表覆盖分类.当目标影像中有少量标注样本时,这种迁移的方法被称为归纳迁移学习(Inductive Transfer Learning, ITL),当目标影像中没有任何标签样本时,则为直推式迁移学习(Transductive Transfer Learning, TTL)[6]. ...
迁移学习支持下的遥感影像对象级分类样本自动选择方法
2
2014
... 样本迁移是近年来流行的一种基于迁移学习(Transfer Learning, TL)的样本提取思想,相比传统方法而言,样本迁移避免了大量外业调查工作,有效地缩短了采样时间,减轻了分类操作人员的工作负担,节省了所需经费.近年来,吴田军和林聪等[6-7]的研究基于迁移学习的思想,通过往期产品向目标影像进行样本的转移,使得采样的工作量和时间大大减少,且在分类结果上具有良好的表现.刘万军等[8]通过迁移学习思想,结合光谱相似度方法,解决了小样本的问题.Pan等[9]在变化向量分析的方法的基础上提出基于对象的扩展变化向量检测方法进行样本的迁移,通过支持向量机(Support Vector Machine, SVM)进行分类,较传统的基于像元的向量变化检测方法分类精度有了明显提升. ...
... 土地资源作为重要自然资源和社会经济资源,具有整体性、位置固定性和生产性等属性,基于这些特性,一定区域的土地表层覆盖随着社会经济发展发生一定变化的同时,存在大量土地的地表覆盖仍然维持其原有状态.而遥感影像分类的基础就在于,相同的地物具有共同的光谱或形态特征.实地采样人工解译没有充分利用未改变的地物光谱特征,降低了分类时效性.假设已有地表覆产品对应时相的遥感影像数据集为,待分类时相的遥感影像数据集为,m为波段数,n为像素数.则存在X的时相到Y的时相,未发生变化耕地、建筑、水域等地物,各类地物光谱分布的统计差异具有鲁棒性,其对应.样本迁移的工作就是在待分类影像中没有发生改变的地物上采集样本,用于对影像进行地表覆盖分类.当目标影像中有少量标注样本时,这种迁移的方法被称为归纳迁移学习(Inductive Transfer Learning, ITL),当目标影像中没有任何标签样本时,则为直推式迁移学习(Transductive Transfer Learning, TTL)[6]. ...
样本迁移支持下的遥感影像自动分类方法
1
2018
... 样本迁移是近年来流行的一种基于迁移学习(Transfer Learning, TL)的样本提取思想,相比传统方法而言,样本迁移避免了大量外业调查工作,有效地缩短了采样时间,减轻了分类操作人员的工作负担,节省了所需经费.近年来,吴田军和林聪等[6-7]的研究基于迁移学习的思想,通过往期产品向目标影像进行样本的转移,使得采样的工作量和时间大大减少,且在分类结果上具有良好的表现.刘万军等[8]通过迁移学习思想,结合光谱相似度方法,解决了小样本的问题.Pan等[9]在变化向量分析的方法的基础上提出基于对象的扩展变化向量检测方法进行样本的迁移,通过支持向量机(Support Vector Machine, SVM)进行分类,较传统的基于像元的向量变化检测方法分类精度有了明显提升. ...
样本迁移支持下的遥感影像自动分类方法
1
2018
... 样本迁移是近年来流行的一种基于迁移学习(Transfer Learning, TL)的样本提取思想,相比传统方法而言,样本迁移避免了大量外业调查工作,有效地缩短了采样时间,减轻了分类操作人员的工作负担,节省了所需经费.近年来,吴田军和林聪等[6-7]的研究基于迁移学习的思想,通过往期产品向目标影像进行样本的转移,使得采样的工作量和时间大大减少,且在分类结果上具有良好的表现.刘万军等[8]通过迁移学习思想,结合光谱相似度方法,解决了小样本的问题.Pan等[9]在变化向量分析的方法的基础上提出基于对象的扩展变化向量检测方法进行样本的迁移,通过支持向量机(Support Vector Machine, SVM)进行分类,较传统的基于像元的向量变化检测方法分类精度有了明显提升. ...
基于Fisher准则和TrAdaboost的高光谱相似样本分类算法
1
2018
... 样本迁移是近年来流行的一种基于迁移学习(Transfer Learning, TL)的样本提取思想,相比传统方法而言,样本迁移避免了大量外业调查工作,有效地缩短了采样时间,减轻了分类操作人员的工作负担,节省了所需经费.近年来,吴田军和林聪等[6-7]的研究基于迁移学习的思想,通过往期产品向目标影像进行样本的转移,使得采样的工作量和时间大大减少,且在分类结果上具有良好的表现.刘万军等[8]通过迁移学习思想,结合光谱相似度方法,解决了小样本的问题.Pan等[9]在变化向量分析的方法的基础上提出基于对象的扩展变化向量检测方法进行样本的迁移,通过支持向量机(Support Vector Machine, SVM)进行分类,较传统的基于像元的向量变化检测方法分类精度有了明显提升. ...
基于Fisher准则和TrAdaboost的高光谱相似样本分类算法
1
2018
... 样本迁移是近年来流行的一种基于迁移学习(Transfer Learning, TL)的样本提取思想,相比传统方法而言,样本迁移避免了大量外业调查工作,有效地缩短了采样时间,减轻了分类操作人员的工作负担,节省了所需经费.近年来,吴田军和林聪等[6-7]的研究基于迁移学习的思想,通过往期产品向目标影像进行样本的转移,使得采样的工作量和时间大大减少,且在分类结果上具有良好的表现.刘万军等[8]通过迁移学习思想,结合光谱相似度方法,解决了小样本的问题.Pan等[9]在变化向量分析的方法的基础上提出基于对象的扩展变化向量检测方法进行样本的迁移,通过支持向量机(Support Vector Machine, SVM)进行分类,较传统的基于像元的向量变化检测方法分类精度有了明显提升. ...
Updating of land cover maps and change analysis using GlobeLand30 product: A case study in Shanghai metropolitan area,China
1
2020
... 样本迁移是近年来流行的一种基于迁移学习(Transfer Learning, TL)的样本提取思想,相比传统方法而言,样本迁移避免了大量外业调查工作,有效地缩短了采样时间,减轻了分类操作人员的工作负担,节省了所需经费.近年来,吴田军和林聪等[6-7]的研究基于迁移学习的思想,通过往期产品向目标影像进行样本的转移,使得采样的工作量和时间大大减少,且在分类结果上具有良好的表现.刘万军等[8]通过迁移学习思想,结合光谱相似度方法,解决了小样本的问题.Pan等[9]在变化向量分析的方法的基础上提出基于对象的扩展变化向量检测方法进行样本的迁移,通过支持向量机(Support Vector Machine, SVM)进行分类,较传统的基于像元的向量变化检测方法分类精度有了明显提升. ...
Fully convolutional networks with multiscale 3D filters and Transfer Learning for change detection in high spatial resolution satellite images
1
2020
... 此外,深度学习(Deep Learning, DL)的方法也被引入到迁移学习的遥感影像分类中,除了良好的分类性能,还提供了强大的泛化能力以及伪标签生成,在一系列研究中取得非常良好的结果.Song等[10]提出了一种基于迁移学习的三维滤波器深度学习框架,通过对训练集进行语义分割完成样本知识的迁移,提高变化检测的精度.Rafeal等[11]比较不同神经网络深度学习模型和不同训练集上的迁移学习,肯定了迁移学习在遥感图像分类上的有效性.但是,深度学习方法也存在明显的缺点,方法的笨重决定其对设备算力的要求较高,运行时间较长以及对于跨领域的应用需求者而言具有较高的学习成本.对于很多地学和环境生态学研究人员而言,地表覆盖分类结果作为应用需求,只是研究的重要参数而不是研究主体.在精度满足应用要求的前提下,耗时、耗算力且学习成本更高的深度学习相比更快速便捷的机器学习方法对于精度的有限提升对用户不具有足够的吸引力. ...
Convolutional neural Network for remote sensing scene classification: Transfer Learning Analysis
1
2020
... 此外,深度学习(Deep Learning, DL)的方法也被引入到迁移学习的遥感影像分类中,除了良好的分类性能,还提供了强大的泛化能力以及伪标签生成,在一系列研究中取得非常良好的结果.Song等[10]提出了一种基于迁移学习的三维滤波器深度学习框架,通过对训练集进行语义分割完成样本知识的迁移,提高变化检测的精度.Rafeal等[11]比较不同神经网络深度学习模型和不同训练集上的迁移学习,肯定了迁移学习在遥感图像分类上的有效性.但是,深度学习方法也存在明显的缺点,方法的笨重决定其对设备算力的要求较高,运行时间较长以及对于跨领域的应用需求者而言具有较高的学习成本.对于很多地学和环境生态学研究人员而言,地表覆盖分类结果作为应用需求,只是研究的重要参数而不是研究主体.在精度满足应用要求的前提下,耗时、耗算力且学习成本更高的深度学习相比更快速便捷的机器学习方法对于精度的有限提升对用户不具有足够的吸引力. ...
时空融合技术在区域地表覆盖时序分类中的应用
1
2021
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
时空融合技术在区域地表覆盖时序分类中的应用
1
2021
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
基于随机森林的ICESat-2卫星数据地表覆盖分类
0
2020
基于随机森林的ICESat-2卫星数据地表覆盖分类
0
2020
特征优选的GF-2影像湿地地表覆盖要素提取
1
2018
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
特征优选的GF-2影像湿地地表覆盖要素提取
1
2018
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
How many trees in a random forest
1
2012
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
On the selection of decision trees in Random Forests
1
2009
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
An Ensemble of Optimal Trees for Software Development Effort Estimation
1
2018
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
Meta-XGBoost for hyperspectral image classification using Extended MSER-Guided morphological profiles
1
2020
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
Search for the smallest random forest
1
2009
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
Ensemble pruning for glaucoma detection in an unbalanced data set
1
2016
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
Ensemble of optimal trees, random forest and random projection ensemble classification
2
2020
... 对于机器学习分类器的优选,运算时间和分类精度都是重要考量因素.随机森林(Random Forest, RF)算法作为机器学习中最为经典的一种算法,大量研究表明,随机森林方法在不同研究区以及数据源的遥感影像分类工作中均取得良好的表现[12-14].此外,极端随机树ExtraTrees(Extremely Randomized Trees, ExT)算法是另一种决策树集成算法,与随机森林算法非常相似,区别在于节点分裂方式和生长树的采样方式[5].然而,RF等方法的总体预测误差与森林中单株树木的强度及其多样性密切相关,因而生成的随机树森林中的树木达到一定数量后,增加树的数量不能提高预测精度[15].而对森林中的决策树生长进行优化,可以减轻计算负担,提高分类速度[16-17].因此,优化决策树节点和优选随机森林的树木是解决随机森林冗余的两大重要方法.极端梯度提升树(Extreme Gradient Boosting, XGBoost)算法对节点进行优化,是一个增强树模型[18].此外,移除冗余树木和整体修剪是另一思路[19-20].Khan等[21]基于Brier评分提出了最优树集成方法(Ensemble of Optimal Trees,OTE),对经济、环境、体育、互联网、生命和健康等领域的35个数据集进行测试,并将分类和回归的结果同神经网络、决策树、随机森林和支持向量机等传统机器学习方法进行对比,结果表明,在大多数情况下,集合的规模显著减小,并且获得了更好的结果.虽然OTE方法在其他数据集上取得了良好的表现,但是作为一种比较年轻的机器学习方法,对于多光谱遥感影像的光谱-空间特征相结合地表覆盖分类这一研究方向,OTE性能仍然有待探究. ...
... 随机森林通过Bagging和随机空间子集,引入了树的基本模型以及节点分化的随机性[33].随机森林由于存在大量的冗余树木往往规模很大,为削减冗余树木,在保持森林性能的基础上最小化森林的规模,Khan等[21]提出了最优树集成的方法,该方法利用未被解释的方差所反映的树木多样性和个体精度进行选择,从而细化随机森林.研究采用最优树集成方法进行遥感影像的地表覆盖分类,将训练数据随机划分为两个互不重叠的子集和;接下来,对第一个子集,在T自助法采集的样本上生长分类树.同时,从整个项目属性集d中选择 p < d 特征的随机样本.这给树木增加了额外的随机性.由于自助方法的使用,样本中会有一些观测值被遗漏,这些被称为袋外(OOB)观测值.后者不参加树的训练.它们被用来估计建立在自举样本上的每棵树的无法解释的方差.然后,根据无法解释的差异,按照升序对树进行分类,并选择排名最高的 M 棵树.树木的选择和组合如下进行: ...
中亚阿姆河跨境流域景观生态风险时空演变特征分析
2
2022
... 阿姆河三角洲位于阿姆河流域下游地区,由图雅姆雍起至梅杜热臣斯奇地区,地跨乌兹别克斯坦和土库曼斯坦两个国家.该区南起图雅姆雍水库,北至咸海湖盆,东临克孜勒库姆沙漠,西接乌斯泰尔特高原,面积3.6万km2.帕米尔高山上的大型永久冰川和积雪区是阿姆河的发源地,是阿姆河的主要水源,该地区东部和南部均与中亚半沙漠地带接壤,其特点是具有低降水和高辐照度的极端大陆性气候[22],年平均降水量为80~120 mm.蒸散量大大超过年平均降水量.由于夏季的大风和高温[23-24],年蒸发量非常高(约1 500 mm).因此,大多数地区的水文平衡为负,生产生活用水依赖于河流的淡水流入[25].尤其是位于乌兹别克斯坦的花剌子模省和卡拉卡尔帕克斯坦共和国,灌溉农业是区域经济的支柱[26].由于缺水以及不合理灌溉事实上,浅层含盐地下水位广泛存在,该地区大多数农田受到不同程度土壤盐分的影响,进而导致土地退化[22, 27].因此,阿姆河三角洲的特殊性就在于,不仅天然植被(草地、灌丛等)受到水分条件限制而具有复杂的生长策略,作物种植区因为盐渍化程度而具有生长良好、生长不健康乃至休耕等复杂的状态.由此可见,地表覆盖分类对于阿姆河三角洲荒漠化和盐渍化监测而言是必不可少的一项工作. ...
... [22, 27].因此,阿姆河三角洲的特殊性就在于,不仅天然植被(草地、灌丛等)受到水分条件限制而具有复杂的生长策略,作物种植区因为盐渍化程度而具有生长良好、生长不健康乃至休耕等复杂的状态.由此可见,地表覆盖分类对于阿姆河三角洲荒漠化和盐渍化监测而言是必不可少的一项工作. ...
中亚阿姆河跨境流域景观生态风险时空演变特征分析
2
2022
... 阿姆河三角洲位于阿姆河流域下游地区,由图雅姆雍起至梅杜热臣斯奇地区,地跨乌兹别克斯坦和土库曼斯坦两个国家.该区南起图雅姆雍水库,北至咸海湖盆,东临克孜勒库姆沙漠,西接乌斯泰尔特高原,面积3.6万km2.帕米尔高山上的大型永久冰川和积雪区是阿姆河的发源地,是阿姆河的主要水源,该地区东部和南部均与中亚半沙漠地带接壤,其特点是具有低降水和高辐照度的极端大陆性气候[22],年平均降水量为80~120 mm.蒸散量大大超过年平均降水量.由于夏季的大风和高温[23-24],年蒸发量非常高(约1 500 mm).因此,大多数地区的水文平衡为负,生产生活用水依赖于河流的淡水流入[25].尤其是位于乌兹别克斯坦的花剌子模省和卡拉卡尔帕克斯坦共和国,灌溉农业是区域经济的支柱[26].由于缺水以及不合理灌溉事实上,浅层含盐地下水位广泛存在,该地区大多数农田受到不同程度土壤盐分的影响,进而导致土地退化[22, 27].因此,阿姆河三角洲的特殊性就在于,不仅天然植被(草地、灌丛等)受到水分条件限制而具有复杂的生长策略,作物种植区因为盐渍化程度而具有生长良好、生长不健康乃至休耕等复杂的状态.由此可见,地表覆盖分类对于阿姆河三角洲荒漠化和盐渍化监测而言是必不可少的一项工作. ...
... [22, 27].因此,阿姆河三角洲的特殊性就在于,不仅天然植被(草地、灌丛等)受到水分条件限制而具有复杂的生长策略,作物种植区因为盐渍化程度而具有生长良好、生长不健康乃至休耕等复杂的状态.由此可见,地表覆盖分类对于阿姆河三角洲荒漠化和盐渍化监测而言是必不可少的一项工作. ...
An integrated assessment of runoff dynamics in the Amu Darya River Basin: Confronting climate change and multiple human activities,1960-2017
1
2021
... 阿姆河三角洲位于阿姆河流域下游地区,由图雅姆雍起至梅杜热臣斯奇地区,地跨乌兹别克斯坦和土库曼斯坦两个国家.该区南起图雅姆雍水库,北至咸海湖盆,东临克孜勒库姆沙漠,西接乌斯泰尔特高原,面积3.6万km2.帕米尔高山上的大型永久冰川和积雪区是阿姆河的发源地,是阿姆河的主要水源,该地区东部和南部均与中亚半沙漠地带接壤,其特点是具有低降水和高辐照度的极端大陆性气候[22],年平均降水量为80~120 mm.蒸散量大大超过年平均降水量.由于夏季的大风和高温[23-24],年蒸发量非常高(约1 500 mm).因此,大多数地区的水文平衡为负,生产生活用水依赖于河流的淡水流入[25].尤其是位于乌兹别克斯坦的花剌子模省和卡拉卡尔帕克斯坦共和国,灌溉农业是区域经济的支柱[26].由于缺水以及不合理灌溉事实上,浅层含盐地下水位广泛存在,该地区大多数农田受到不同程度土壤盐分的影响,进而导致土地退化[22, 27].因此,阿姆河三角洲的特殊性就在于,不仅天然植被(草地、灌丛等)受到水分条件限制而具有复杂的生长策略,作物种植区因为盐渍化程度而具有生长良好、生长不健康乃至休耕等复杂的状态.由此可见,地表覆盖分类对于阿姆河三角洲荒漠化和盐渍化监测而言是必不可少的一项工作. ...
Impacts of historical land use/cover change (1980–2015) on summer climate in the Aral Sea Region
1
2021
... 阿姆河三角洲位于阿姆河流域下游地区,由图雅姆雍起至梅杜热臣斯奇地区,地跨乌兹别克斯坦和土库曼斯坦两个国家.该区南起图雅姆雍水库,北至咸海湖盆,东临克孜勒库姆沙漠,西接乌斯泰尔特高原,面积3.6万km2.帕米尔高山上的大型永久冰川和积雪区是阿姆河的发源地,是阿姆河的主要水源,该地区东部和南部均与中亚半沙漠地带接壤,其特点是具有低降水和高辐照度的极端大陆性气候[22],年平均降水量为80~120 mm.蒸散量大大超过年平均降水量.由于夏季的大风和高温[23-24],年蒸发量非常高(约1 500 mm).因此,大多数地区的水文平衡为负,生产生活用水依赖于河流的淡水流入[25].尤其是位于乌兹别克斯坦的花剌子模省和卡拉卡尔帕克斯坦共和国,灌溉农业是区域经济的支柱[26].由于缺水以及不合理灌溉事实上,浅层含盐地下水位广泛存在,该地区大多数农田受到不同程度土壤盐分的影响,进而导致土地退化[22, 27].因此,阿姆河三角洲的特殊性就在于,不仅天然植被(草地、灌丛等)受到水分条件限制而具有复杂的生长策略,作物种植区因为盐渍化程度而具有生长良好、生长不健康乃至休耕等复杂的状态.由此可见,地表覆盖分类对于阿姆河三角洲荒漠化和盐渍化监测而言是必不可少的一项工作. ...
Response of carbon dynamics to climate change varied among different vegetation types in Central Asia
1
2018
... 阿姆河三角洲位于阿姆河流域下游地区,由图雅姆雍起至梅杜热臣斯奇地区,地跨乌兹别克斯坦和土库曼斯坦两个国家.该区南起图雅姆雍水库,北至咸海湖盆,东临克孜勒库姆沙漠,西接乌斯泰尔特高原,面积3.6万km2.帕米尔高山上的大型永久冰川和积雪区是阿姆河的发源地,是阿姆河的主要水源,该地区东部和南部均与中亚半沙漠地带接壤,其特点是具有低降水和高辐照度的极端大陆性气候[22],年平均降水量为80~120 mm.蒸散量大大超过年平均降水量.由于夏季的大风和高温[23-24],年蒸发量非常高(约1 500 mm).因此,大多数地区的水文平衡为负,生产生活用水依赖于河流的淡水流入[25].尤其是位于乌兹别克斯坦的花剌子模省和卡拉卡尔帕克斯坦共和国,灌溉农业是区域经济的支柱[26].由于缺水以及不合理灌溉事实上,浅层含盐地下水位广泛存在,该地区大多数农田受到不同程度土壤盐分的影响,进而导致土地退化[22, 27].因此,阿姆河三角洲的特殊性就在于,不仅天然植被(草地、灌丛等)受到水分条件限制而具有复杂的生长策略,作物种植区因为盐渍化程度而具有生长良好、生长不健康乃至休耕等复杂的状态.由此可见,地表覆盖分类对于阿姆河三角洲荒漠化和盐渍化监测而言是必不可少的一项工作. ...
乌兹别克斯坦灌溉农业发展及其对生态环境和经济发展的影响
1
2021
... 阿姆河三角洲位于阿姆河流域下游地区,由图雅姆雍起至梅杜热臣斯奇地区,地跨乌兹别克斯坦和土库曼斯坦两个国家.该区南起图雅姆雍水库,北至咸海湖盆,东临克孜勒库姆沙漠,西接乌斯泰尔特高原,面积3.6万km2.帕米尔高山上的大型永久冰川和积雪区是阿姆河的发源地,是阿姆河的主要水源,该地区东部和南部均与中亚半沙漠地带接壤,其特点是具有低降水和高辐照度的极端大陆性气候[22],年平均降水量为80~120 mm.蒸散量大大超过年平均降水量.由于夏季的大风和高温[23-24],年蒸发量非常高(约1 500 mm).因此,大多数地区的水文平衡为负,生产生活用水依赖于河流的淡水流入[25].尤其是位于乌兹别克斯坦的花剌子模省和卡拉卡尔帕克斯坦共和国,灌溉农业是区域经济的支柱[26].由于缺水以及不合理灌溉事实上,浅层含盐地下水位广泛存在,该地区大多数农田受到不同程度土壤盐分的影响,进而导致土地退化[22, 27].因此,阿姆河三角洲的特殊性就在于,不仅天然植被(草地、灌丛等)受到水分条件限制而具有复杂的生长策略,作物种植区因为盐渍化程度而具有生长良好、生长不健康乃至休耕等复杂的状态.由此可见,地表覆盖分类对于阿姆河三角洲荒漠化和盐渍化监测而言是必不可少的一项工作. ...
乌兹别克斯坦灌溉农业发展及其对生态环境和经济发展的影响
1
2021
... 阿姆河三角洲位于阿姆河流域下游地区,由图雅姆雍起至梅杜热臣斯奇地区,地跨乌兹别克斯坦和土库曼斯坦两个国家.该区南起图雅姆雍水库,北至咸海湖盆,东临克孜勒库姆沙漠,西接乌斯泰尔特高原,面积3.6万km2.帕米尔高山上的大型永久冰川和积雪区是阿姆河的发源地,是阿姆河的主要水源,该地区东部和南部均与中亚半沙漠地带接壤,其特点是具有低降水和高辐照度的极端大陆性气候[22],年平均降水量为80~120 mm.蒸散量大大超过年平均降水量.由于夏季的大风和高温[23-24],年蒸发量非常高(约1 500 mm).因此,大多数地区的水文平衡为负,生产生活用水依赖于河流的淡水流入[25].尤其是位于乌兹别克斯坦的花剌子模省和卡拉卡尔帕克斯坦共和国,灌溉农业是区域经济的支柱[26].由于缺水以及不合理灌溉事实上,浅层含盐地下水位广泛存在,该地区大多数农田受到不同程度土壤盐分的影响,进而导致土地退化[22, 27].因此,阿姆河三角洲的特殊性就在于,不仅天然植被(草地、灌丛等)受到水分条件限制而具有复杂的生长策略,作物种植区因为盐渍化程度而具有生长良好、生长不健康乃至休耕等复杂的状态.由此可见,地表覆盖分类对于阿姆河三角洲荒漠化和盐渍化监测而言是必不可少的一项工作. ...
Improving remote sensing-based net primary production estimation in the grazed land with defoliation formulation model
1
2019
... 阿姆河三角洲位于阿姆河流域下游地区,由图雅姆雍起至梅杜热臣斯奇地区,地跨乌兹别克斯坦和土库曼斯坦两个国家.该区南起图雅姆雍水库,北至咸海湖盆,东临克孜勒库姆沙漠,西接乌斯泰尔特高原,面积3.6万km2.帕米尔高山上的大型永久冰川和积雪区是阿姆河的发源地,是阿姆河的主要水源,该地区东部和南部均与中亚半沙漠地带接壤,其特点是具有低降水和高辐照度的极端大陆性气候[22],年平均降水量为80~120 mm.蒸散量大大超过年平均降水量.由于夏季的大风和高温[23-24],年蒸发量非常高(约1 500 mm).因此,大多数地区的水文平衡为负,生产生活用水依赖于河流的淡水流入[25].尤其是位于乌兹别克斯坦的花剌子模省和卡拉卡尔帕克斯坦共和国,灌溉农业是区域经济的支柱[26].由于缺水以及不合理灌溉事实上,浅层含盐地下水位广泛存在,该地区大多数农田受到不同程度土壤盐分的影响,进而导致土地退化[22, 27].因此,阿姆河三角洲的特殊性就在于,不仅天然植被(草地、灌丛等)受到水分条件限制而具有复杂的生长策略,作物种植区因为盐渍化程度而具有生长良好、生长不健康乃至休耕等复杂的状态.由此可见,地表覆盖分类对于阿姆河三角洲荒漠化和盐渍化监测而言是必不可少的一项工作. ...
Landsat 8: Science and product vision for terrestrial global change research
1
2014
... 研究采用Landsat-8 OLI影像(http:∥earthexplorer.usgs.gov),Landsat数据的空间分辨率为30 m,波段范围为0.45~2.35 µm,具有易于获取和方便预处理等优点[28].最为重要的是,Landsat产品时间跨度较长,可以为长时序地表覆盖变化监测提供数据支撑[29-30].研究使用的数据级别为L1T1,研究区共覆盖5幅影像,选取时间段为7月15日至9月15日.预处理基于ENVI5.3,对原始影像进行了几何配准、裁剪、镶嵌、辐射定标、大气校正等一系列操作. ...
Continuous change detection and classification of land cover using all available Landsat data
1
2014
... 研究采用Landsat-8 OLI影像(http:∥earthexplorer.usgs.gov),Landsat数据的空间分辨率为30 m,波段范围为0.45~2.35 µm,具有易于获取和方便预处理等优点[28].最为重要的是,Landsat产品时间跨度较长,可以为长时序地表覆盖变化监测提供数据支撑[29-30].研究使用的数据级别为L1T1,研究区共覆盖5幅影像,选取时间段为7月15日至9月15日.预处理基于ENVI5.3,对原始影像进行了几何配准、裁剪、镶嵌、辐射定标、大气校正等一系列操作. ...
全球30 m地表覆盖定量遥感分类与制图研究
1
2020
... 研究采用Landsat-8 OLI影像(http:∥earthexplorer.usgs.gov),Landsat数据的空间分辨率为30 m,波段范围为0.45~2.35 µm,具有易于获取和方便预处理等优点[28].最为重要的是,Landsat产品时间跨度较长,可以为长时序地表覆盖变化监测提供数据支撑[29-30].研究使用的数据级别为L1T1,研究区共覆盖5幅影像,选取时间段为7月15日至9月15日.预处理基于ENVI5.3,对原始影像进行了几何配准、裁剪、镶嵌、辐射定标、大气校正等一系列操作. ...
全球30 m地表覆盖定量遥感分类与制图研究
1
2020
... 研究采用Landsat-8 OLI影像(http:∥earthexplorer.usgs.gov),Landsat数据的空间分辨率为30 m,波段范围为0.45~2.35 µm,具有易于获取和方便预处理等优点[28].最为重要的是,Landsat产品时间跨度较长,可以为长时序地表覆盖变化监测提供数据支撑[29-30].研究使用的数据级别为L1T1,研究区共覆盖5幅影像,选取时间段为7月15日至9月15日.预处理基于ENVI5.3,对原始影像进行了几何配准、裁剪、镶嵌、辐射定标、大气校正等一系列操作. ...
Finer resolution observation and monitoring of global land cover: first mapping results with Landsat TM and ETM+data
1
2013
... 为了方便样本的迁移,研究使用的样本标签来自FROM-GLC 2015,数据来源于清华大学地球系统科学系(http:∥data.ess.tsinghua.edu.cn),空间分辨率为30 m,该系列最早一期的产品基于2010年的Landsat图像生成[31].FROM-GLC系列产品在随后更新到了2015年,最低精度也由63.69%提升至72.43%. ...
Threshold selection method from gray-level histogram
1
1979
... 由于不同地物所具有的不同光谱特征,对于,可以找到某一阈值,将所有像元分成两个部分,即来自没有发生变化地物的像元和来自已经发生变化地物的像元.研究采用大津法[32](Ostu’s)对结果进行阈值分割,找到未发生变化的地物斑块,然后进行采样. ...
Random forests
1
2001
... 随机森林通过Bagging和随机空间子集,引入了树的基本模型以及节点分化的随机性[33].随机森林由于存在大量的冗余树木往往规模很大,为削减冗余树木,在保持森林性能的基础上最小化森林的规模,Khan等[21]提出了最优树集成的方法,该方法利用未被解释的方差所反映的树木多样性和个体精度进行选择,从而细化随机森林.研究采用最优树集成方法进行遥感影像的地表覆盖分类,将训练数据随机划分为两个互不重叠的子集和;接下来,对第一个子集,在T自助法采集的样本上生长分类树.同时,从整个项目属性集d中选择 p < d 特征的随机样本.这给树木增加了额外的随机性.由于自助方法的使用,样本中会有一些观测值被遗漏,这些被称为袋外(OOB)观测值.后者不参加树的训练.它们被用来估计建立在自举样本上的每棵树的无法解释的方差.然后,根据无法解释的差异,按照升序对树进行分类,并选择排名最高的 M 棵树.树木的选择和组合如下进行: ...


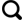





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}