

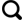


1 引 言
PM2.5的主要监测方法有地面站点监测和卫星遥感监测。地面站点监测主要是基于定点采样技术获取数据,虽然可以精确获得实时的结果,但是仅能反映小范围内的空气污染情况,而且站点稀少且分布不均,很多地区无法测量,通常还需要辅助化学分析仪器,费用昂贵[10-11]。卫星遥感监测是对卫星观测数据与地面实测PM2.5的关系进行统计分析。Jun等[12]利用美国阿拉巴马州杰斐逊县7个地面站点测量的PM2.5浓度与中分辨率成像光谱仪(Moderate Resolution Imaging Spectroradiometer,MODIS)气溶胶产品进行相关性分析,验证了PM2.5与气溶胶之间线性相关系数R为0.7;Song等[13]利用卫星AOD数据建立地理加权回归模型,该模型能够解释地面PM2.5浓度73.8%的变异性;Hu等[14]利用美国大陆监测PM2.5浓度、MODIS 10 km AOD数据和土地覆盖等数据构建随机森林模型,估算2011年美国周边地区24 h地面PM2.5的日平均浓度;贾松林等[15]构建了适应于北京及周边地区PM2.5与AOD的一元简单线性、多元线性和非线性回归模型,其反演结果R2分别为0.301 2、0.554 9、0.743 1,3种模型均存在着高估和低估的现象。卫星遥感具有大面积同步观测、获取信息的速度快、周期短、手段多、信息量丰富等特点,用于PM2.5的大面积反演,可有效弥补地面监测的不足[16],卫星遥感已经成为监测PM2.5的一种重要手段。
2 研究区域及数据来源
2.1 研究区概况
以北京市、天津市、河北省3个行政区域作为研究区,以下简称京津冀。京津冀位于华北平原,地理坐标为36°01′~42°37′ N,113°04′~119°53′ E。北接辽宁、内蒙古地区;西邻山西省,左拥太行山;毗邻山东与河南;以东紧傍东海湾。京津冀地区地形地貌复杂多样,由东南向西北逐级上升,平原、盆地、丘陵、山地、高原依次排列;燕山山脉东西走向,太行山山脉东北西南走向。
京津冀地区属于温暖半湿润大陆性季风型气候,雨水充足,四季分明,气候温暖。春秋两季时间短,冬季时间长,由东南向西北平均气温逐渐降低,南北温差很大。春季降水少,夏季多暴雨和阵雨,西北部降水低于东南部,主要降水集中在夏季,黄海岸比较湿润,渤海岸降水较少,比较干燥。
2.2 数据来源
2.2.1 遥感气溶胶数据
MODIS传感器是美国国家航空航天局(National Aeronautics and Space Administration,NASA)地球观测系统(Earth Observing system,EOS)系列卫星中“图谱合一”的光学传感器,搭载Terra和Aqua卫星上[19]。实验使用的大气气溶胶光学厚度数据为MOD/MYD04_3K(MODIS Terra/Aqua Aerosol 5-Min L2 Swath 3km)产品数据(
nasa.gov/search/order/4/MOD04_3K-61),该数据可用来获取全球海洋和陆地环境的大气气溶胶光学特性和质量浓度,其空间分辨率为3 km,版本为C6,以HDF4格式提供。本研究选用京津冀地区2018~2020年的AOD产品数据,对其进行重投影、裁剪等预处理。由于受雨、雪、云和地表覆盖等条件影响有部分AOD值缺失,通过反距离加权插值算法(Inverse Distance Weight,IDW)对影像缺失值进行填充。
2.2.2 气象数据
MERRA-2(The Modern-Era Retrospective analysis for Research and Applications, Version 2)是由NASA戈达德地球科学数据和信息服务中心(Goddard Earth Sciences Data and Information Services Center,GESDISC)在融合多种气象观测资料和卫星数据基础上,生成的MERRA再分析数据集[20]。MERRA-2中包括各种气象变量,其空间分辨率为0.5°×0.625°,时间分辨率为1 h。本研究选用2018~2020年的MERRA-2气象数据(
2.2.3 地面站点PM2.5数据
地面站点实测PM2.5浓度数据来自中国环境监测总站(http:∥www.cnemc.cn/),2018~2020年地面空气监测站点为0~24 h逐小时的PM2.5数据,将地面站点实测数据与AOD数据进行时空匹配。经筛选京津冀地区共78个可用监测站点,其分布如图1所示。
图1

图1
2018~2020京津冀地区地面站点分布图
Fig.1
Distribution map of ground stations in Beijing-Tianjin-Hebei region from 2018 to 2020
3 研究方法
利用MODIS AOD产品、MERRA-2、地面站点PM2.5数据,基于随机森林的机器学习模型,进行京津冀地区PM2.5浓度反演,流程如图2所示。
图2
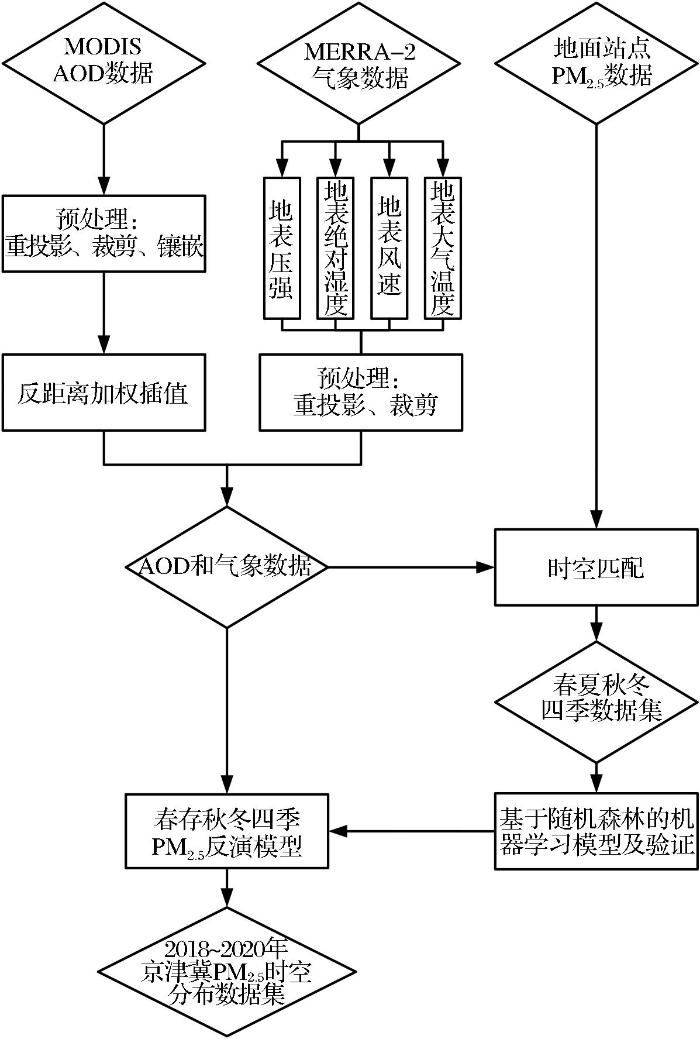
图2
京津冀地区PM2.5浓度反演流程图
Fig.2
Inversion of PM2.5 concentration flow chart in Beijing-Tianjin-Hebei region
(1)对MODIS AOD产品进行重投影、裁剪、镶嵌、反距离加权插值等处理;将MERRA-2数据中气象变量(地表压强、地表绝对湿度、地表风速、地表大气温度)进行提取并预处理。
(2)将AOD、气象变量、地面站点PM2.5在时间和空间上匹配,作为模型训练样本和验证样本。
(3)将数据集分为春夏秋冬进行随机森林模型训练及验证,并统计预测值与实测值误差,统计指标参数包括决定系数(coefficient of determination,R2)、均方根误差(Root Mean Squared Error,RMSE)。
(4)最后,将2018~2020年AOD、气象变量导入模型中,得到京津冀地区PM2.5浓度的空间分布图,并对反演结果分析。
3.1 反距离加权插值
针对AOD由于云层干扰、雨雪天气等原因造成的数据缺失问题,利用反距离加权插值算法进行缺失值填充,反距离加权插值算法是基于相近相似的原理[21],每一个测量点都对预测点具有一定的影响,即权重。权重随着测量点和预测点之间距离的增加而减小,即距离预测点越近则测量点的权重越大,当测量点和预测点之间距离超过一定范围,权重可以忽略不计。幂值控制着权系数随着测量点和预测点之间距离的变化而改变的幅度。计算公式如下:
其中:
其中:p是距离的幂值,通常为0.5~3较合理,本研究设置为2。
其中:(x,y)为预测点坐标;(
3.2 时空匹配
将2018~2020年实验数据按四季分为春(3~5月),夏(6~8月),秋(9~11月),冬(12月,次年1~2月)。将插值之后的AOD数据与地表压强、地表绝对湿度、地表风速、地表大气温度和地面站点PM2.5数值进行时空匹配。
AOD数据时间为国际时间,需要将该数据的国际时间转换为北京时间(UTC/GMT +8),气象数据时间分辨率为1 h,地面站点PM2.5数据监测时间间隔为1 h。以3 a AOD数据为基准进行时空匹配,经过筛选剔除无效值得到春季组19 184条数据集,夏季组19 298条数据集,秋季组13 883条数据集,冬季组13 408条数据集,一共65 773条数据集,图3是各变量数值变化范围的统计直方图。
图3

图3
因变量与自变量统计(最小值、最大值、均值、标准差)
Fig.3
Statistical chart of dependent and independent variables
3.3 AOD-PM2.5反演模型构建
3.3.1 随机森林算法
随机森林选择样本的方法是有放回的随机抽样,所以构建回归树时有一部分样本不被选中,起到了样本内部交叉验证的作用,使模型不易出现过拟合现象。本研究中随机森林算法步骤如下:
(1)样本选择。从原始样本集N中有放回的抽取n个样本,得到一个大小为n的训练集。
(2)生成决策树。在每一轮生成决策树的过程中,从D个特征中随机选择d个特征组成新的特征集,并使用新的特征集生成决策树。生成决策树过程中,每个特征集都是随机抽取的,所以每个决策树都是相互独立的。
(3)组合模型。由于决策树之间相互独立,每个决策树的权重相等,将所有决策树预测结果的均值作为最终预测结果。
随机森林模型最重要的两个参数分别是决策树的个数和决策树最大深度,前者决定了对原始数据集进行有放回抽样生成的子数据集个数;后者在样本数量少或者特征少时,不限制最大深度。
3.3.2 模型拟合评价指标
选择决定系数
其中:Xi 是第i个实测值;
其中:N为训练样本个数;xj 是第j个预测值;yj 是第j个实测值。
3.3.3 模型构建
由于各季节的气象环境和气溶胶物化特性存在较大差异,导致AOD和PM2.5的相关性因季节差异而有所不同,使用长时间序列的样本会降低拟合精度。因此全年或个别时间段的AOD与PM2.5的相关函数并不具有代表性[25]。选择按季节进行分组分别训练模型,可以减少误差,提高模型精度。将数据集分为春、夏、秋、冬4组,通常训练样本分布越均匀,训练的模型可靠性越强,所以每组训练模型时将数据顺序打乱,以保证数据的随机性。以每组80%的数据为训练集,剩下20%为测试集,用于模型精度分析。通过优化决策树的个数和决策树最大深度两个参数以提高模型预测精度[26]。其中决策树的个数取值2~300,间隔为2;决策树最大深度取值2~300,间隔为2。并对随机森林算法得到的各变量重要性大小进行排序。变量重要性是指预测变量对预测精度贡献率的大小,值越大表示变量越重要。在随机森林模型中,其变量重要性为相对重要性,总和为1[27]。
同组训练集和测试集数据打乱的随机因子相同,保证了训练和测试时数据的均匀且防止了因数据的不同导致测试分析的误差。其中春季组训练集有15 347条数据,测试集有38 37条数据;夏季组训练集有15 438条数据,测试集有3 860条数据;秋季组训练集有11 106条数据,测试集有2 777条数据;冬季组训练集有10 726条数据,测试集有2 682条数据。
由图4模型精度分析看到,春季组决策树个数在200之后,决定系数R2稳定在0.76左右,均方根误差RMSE稳定在22左右,随着增加决策树个数,R2和RMSE优化程度很小;决策树最大深度在50到150之间模型R2和RMSE波动较小。夏季组决策树个数在150之后,R2稳定在0.64左右,RMSE稳定在11左右,随着决策树个数增加,R2和RMSE优化程度很小;决策树最大深度在50到100之间模型R2和RMSE波动较小。秋季和冬季决策树个数在200之后R2和RMSE较为稳定,R2在0.83附近波动;决策树最大深度在50之后,R2秋冬季均在0.8处波动,RMSE分别在17和30附近波动,冬季的均方根误差在30左右。春夏秋冬四组模型决策树个数分别取150、200、150、200;决策树最大深度均为100。
图4
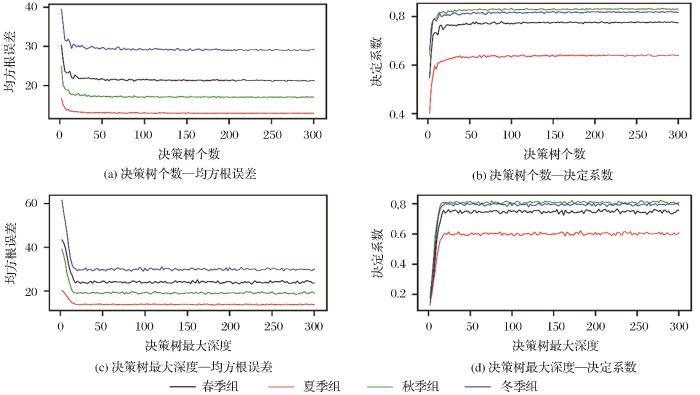
图4
决策树个数和最大深度的参数优化
Fig.4
Parameter optimization of the number and the maximum depth of decision trees
图5(a)是4个季节十次交叉验证结果折线图,决定系数平均值分别为0.78、0.66、0.83、0.83,本文4个季节模型的站点决定系数误差如图5(b)、(c)、(d)、(e)所示,其中站点R2大于等于0.7最多的是冬季,占比87%(78个站点中有68个),最少的是夏季,R2大于等于0.7的占比42%(78个站点有33个)。春夏秋冬四季地面站点平均决定系数分别为0.73、0.58、0.79、0.77,在空间分布方面,保定和沧州表现较好。杨颖川等[28]建立AOD、能见度、PM2.5浓度的三元回归模型,春夏秋冬决定系数分别为0.72、0.87、0.78、0.65,春秋冬3组均低于本研究所建立的模型,但是空间分布趋势与本研究结果一致。王伟齐等[29]研究了北京市12个空气质量监测站PM2.5的5 h和24 h两种时间段平均浓度与AOD的关系模型平均决定系数分别为0.57和0.48。
图5
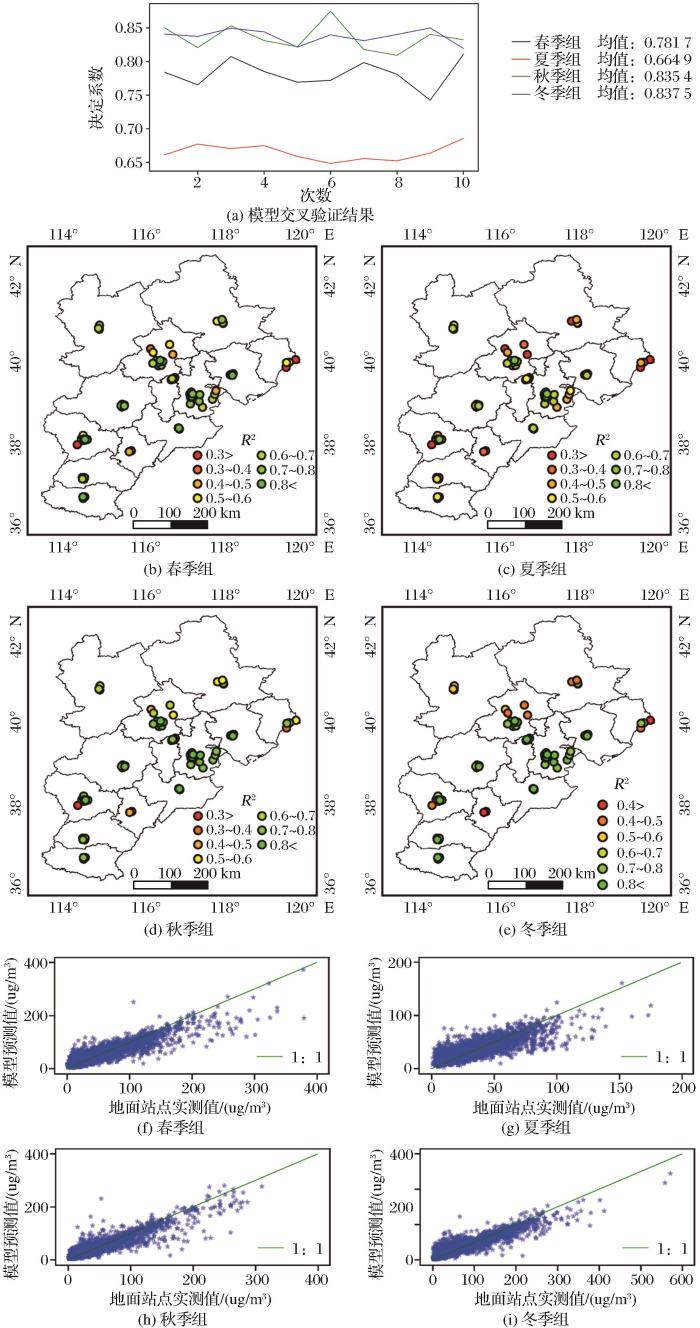
图5(f)、(g)、(h)、(i)是春夏秋冬4组实测值与模型预测值的散点图,其中夏季PM2.5变化相对平缓,但模型决定系数相对较低,可能是由于是夏季气象条件变化比较快,特别是降雨频繁,湿度在时间和空间上变化较快,而夏季模型中湿度所占权重较大,然而较低的气象数据分辨率低并不能充分描述夏季快速变化的气象环境,从而导致夏季模型决定系数不高。从散点图看到,4组均出现了高值低估、低值高估现象,其原因可能为:在污染比较严重的天气下AOD反演失效,缺乏高PM2.5值的反演结果;另一主要原因可能是反距离加权插值结果并不能完全反映出AOD的真实变化,当AOD高值区域缺失,该区域插值点结果有可能被低估。京津冀地区地面监测站点分布不均匀,监测站点主要集中在污染严重的城市区域,污染较轻的郊区和山区站点稀少甚至没有站点监测数据,所以在污染较轻的地区,反距离加权插值结果往往会高估。春夏秋冬4组模型的RMSE分别为20.4、12.6、18.8、26.5,其中春秋冬3组与夏季相比略高,主要原因是春秋冬3个季节的PM2.5浓度较高,夏季PM2.5浓度偏低。此外,气象数据误差和数据时空匹配偏差也可能是导致RMSE较高的一个原因。
4 结果与分析
4.1 单日结果对比
经过模型精度分析,将数据按四季进行分组分别训练模型,春、秋、冬3组预测值与实测值决定系数达到了0.8左右,夏季模型决定系数为0.65。
受云、地表覆盖和气溶胶反演算法的限制,MODIS的AOD产品在空间上常常出现缺失,因此本文采用反距离加权算法进行缺值弥补。图6显示部分AOD数据插值前后的对比,即2019年9月5日、9月21日、9月28日、2020年5月1日。图6(a)、(b)、(c)、(d)为原始AOD数据,图6 (e)、(f)、(g)、(h)是经过反距离加权插值后的AOD数据。从图中可以看到,AOD数据经过反距离加权插值之后,数据保持了空间的连续性,同时与原始AOD数据空间分布趋势一致,未出现明显的区块效应。通过将插值之后的AOD数据和地表压强、地表绝对湿度、地表风速、地表大气温度等气象数据进行时空匹配,反演得到京津冀PM2.5质量浓度图,如图6(i)、(j)、(k)、(l)所示。将反演得到的PM2.5浓度图与插值之后的AOD图对比,PM2.5质量浓度与AOD分布区域有较好的一致性。
图6
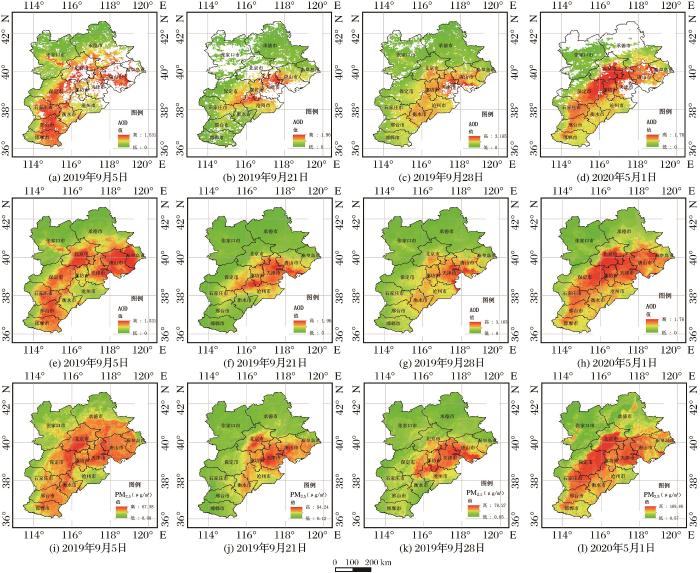
图6
单日反演结果,((a)~(d)为原始AOD数据,(e)~(h)为插值后的AOD,(i)~(l)为反演的PM2.5)
Fig.6
The inversion results in some single days
4.2 季均值结果分析
图7
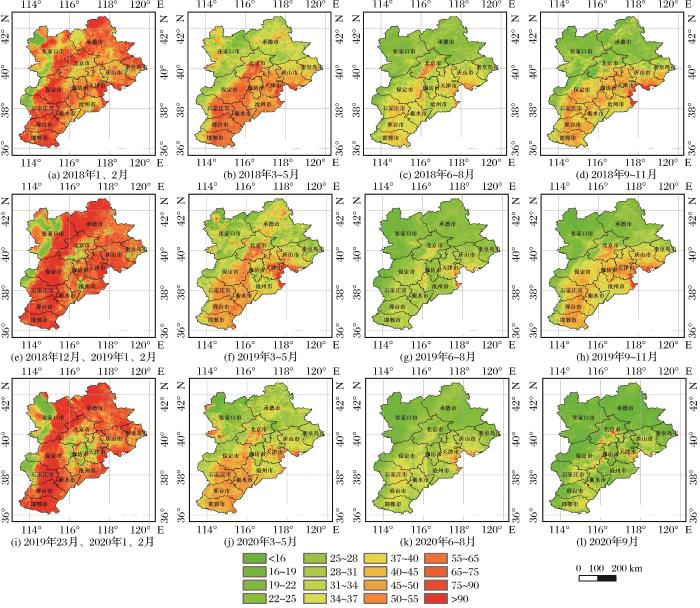
图7
2018~2020年PM2.5季节均值结果
Fig.7
Seasonal average results of PM2.5 during 2018~2020
图8

图8
2018~2020年PM2.5季节均值统计图
Fig.8
Statistical chart of PM2.5’s seasonal mean value during 2018~2020
2018~2020三年的PM2.5随季节变化的规律大致相同,对2019年分析可以看到,冬季是4个季度PM2.5污染浓度分布最广,污染数值最高的季度,其污染浓度值49%集中在60 μg/m3以上,分析原因可能是进入冬季节,随着地面温度降低,边界层下将,大气层结趋于稳定,环境容量较春夏季有所下降,地面气温低会出现“逆温”现象,使得污染物在近地层不断增加,PM2.5达到高浓度水平。并且部分地区开始供暖,化石燃料燃烧排放增加,在静稳条件下,容易出现区域性污染。靠近西北部区域有小部分浓度低值,可能与西北部地势高人口较少,从而人为排放较少有关。
春季相较于冬季PM2.5浓度和高值范围总体有所下降,PM2.5浓度71%集中在30~60 μg/m3,污染主要集中在南部区域,在北部区域污染数值普遍低于30 μg/m3,其主要原因可能是由于河北南部人口密度变大,工业经济发展使用大量能源,城市的快速发展促使城市建设用地急剧增加,城市的建设发展对于PM2.5浓度值的贡献也相应上升。
夏季是一年中PM2.5浓度值最低、污染范围最小、空气质量最好的一个季节。与其他季节相比,PM2.5浓度最大值减小,PM2.5浓度72%集中在15~30 μg/m3之间,得益于夏季地面空气温度高,气温随着海拔升高而降低。下层空气温度高,上层空气温度低,冷热空气上下交替,就会形成对流,大气垂直运动活跃,污染物容易扩散。此外,夏季较频繁的降雨及大风天气,有利于PM2.5的扩散和清除,因而一年中夏季的PM2.5浓度最低。
秋季PM2.5浓度高值区间低于春季和冬季,86%集中在15~45 μg/m3之间,中南部污染相较西北部高一些。与夏季的暴雨相比,秋季的雨水持续时间较短,风速和风力较小,对空气中污染物的冲刷效果不明显,而起到增加空气湿度的作用,潮湿的空气会更容易造成悬浮物的累积。
为保障国家环境安全、应对气候变化和保护生态环境,2018~2020年国家实行蓝天保卫战《三年行动计划》,在京津冀地区采取一系列大气治理的措施,因此总体而言,2020年较2018年环境空气质量有明显改善。
5 结 论
本文采用NASA发布的MODIS L2级气溶胶产品数据、MERRA-2气象数据(表层压强 、表层绝对湿度、表层风速、表层大气温度)和地面站点PM2.5浓度监测数据,按春夏秋冬四季分别构建AOD-PM2.5随机森林算法反演模型,通过模型参数优化,反演出2018~2020年京津冀地区PM2.5浓度值,从而对PM2.5浓度的季节空间分布和变化特征进行分析。得到以下结论:
(1)随机森林算法效率高,对于大量训练样本,随机森林训练速度有优势,实验结果表明,研究搭建的随机森林PM2.5反演模型可以取得较好的PM2.5反演效果。
(2)由于气象原因出现AOD影像缺失问题,本研究使用反距离加权插值算法对图像进行缺失值填补,且图像插值结果较好的反映了AOD的空间分布并未出现明显的区块效应。
(3)由于京津冀地区春夏秋冬季节变化显著,将数据集按照季节分组,分别进行模型训练,春夏秋冬4组模型决定系数均值分别为0.78、0.66、0.83、0.83,模拟精度较高。
通过对PM2.5季节均值反演结果分析,PM2.5浓度分布表现出明显的季节性变化特征,冬季PM2.5污染最严重,春季和秋季次之,夏季最低。大于75 μg/m3的高值区在冬季出现,其主要原因是由于冬季供暖污染物排放浓度高、强度大,导致PM2.5的排放量增加,同时冬季极易出现的“逆温”现象更有利于PM2.5的聚集。夏季是四季中污染程度最轻、空气质量最好的季节。春秋两季污染程度低于冬季,PM2.5浓度空间分布出现“东南高西北地”的特点,PM2.5分布不仅与区域污染物排放有关,同时也与地理条件和地形条件有一定关系。
近年来已经发射的高分辨率卫星越来越多,采用更高空间分辨率的影像用于反演PM2.5是今后的研究重点之一。另外,因云、地表覆盖等因素导致气溶胶数据缺失,更好的插值算法也是研究PM2.5空间分布特征的重点。
大气PM2.5的监测与防治对生态环境的建设和人体健康有着重要的意义,本研究提出了基于随机森林的卫星遥感反演PM2.5的方法,希望有助于进一步提升空气质量的监测能力。
参考文献
The study on air quality change of Nanchang city from 2004 to 2015 years based on satellite remote sensing MODIS data
[J].
基于卫星遥感MODIS数据反演南昌市2004—2015年空气质量变化研究
[J].
Health damages from air pollution in China
[J].
Meteorological influences on PM2.5 and O3 trends and associated health burden since China's clean air actions
[J].
The prospective effects of long-term expo-sure to ambient PM2.5 and constituents on mortality in ru-ral East China
[J].
A critical assessment of high-resolution aerosol optical depth retrievals for fine particulate matter predictions
[J].
Association between particulate air pollution and QT interval duration in an elderly cohort
[J].
Remote sensing retrieval of atmospheric rine particle PM2.5 based on GOCI satellite and its temporal and spatial distribution
[J].
基于GOCI卫星的大气细颗粒物PM2.5的遥感反演及其时空分布规律研究
[J].
Aerosol optical properties study based on ground observation
[D].
基于地基观测的气溶胶光学特性研究
[D].
Spatial and temporal distribution of PM2.5 in Pingxiang city
[J].
萍乡市大气污染PM2.5时空分布规律
[J].
Inversion of PM2.5 concentration in Beijing based on satellite remote sensing and meteorological reanalysis data
[J].
基于卫星遥感和气象再分析资料的北京市PM2.5浓度反演研究
[J].
Es-timating ground-level hourly PM2.5 Concentrations over north China plain with deep neural networks
[J].
Intercomparison between satellite‐derived aerosol optical thickness and PM2.5 mass: Implications for air quality studies
[J].
A satelli-tebased geographically weighted regression model for regional PM2.5 estimation over the Pearl River Delta region in China
[J].
Estimating PM2.5 concentrations in the conterminous united states using the random forest approach
[J].
A study of multiple regression method for estimating concentration of fine particulate matter using satellite remote sensing
[J].
卫星遥感监测近地表细颗粒物多元回归方法研究
[J].
High resolution PM2.5 estimation using remote sensing data based on random forest——A case study of Guangdong,China
[J].
基于随机森林的高分辨率PM2.5遥感反演——以广东省为例
[J].
Estimating ground-level PM2.5 in the eastern United States using satellite remote sensing
[J].
City-level air quality improvement in the Beijing-Tianjin-Hebei region from 2016/17 to 2017/18 hea-ting seasons: Attributions and process analysis
[J].
Estimation and spatial-temporal distribution characteristics of PM2.5 concentration by remote sensing in China in 2015
[J].
2015年中国PM2.5浓度遥感估算与时空分布特征
[J].
Spatial and temporal variability of aerosol optical depth in China based on MERRA-2 data
[D].
基于MERRA-2数据的中国气溶胶光学厚度时空变化研究
[D].
Accuracy of interpolation techniques for the derivation of digital elevation models in relation to landform types and data density
[J].
Estimation of CDOM concentration in inland lake based on random forest using Sentinel-3A OLCI
[J].
基于随机森林的内陆湖泊水体有色可溶性有机物(CDOM)浓度遥感估算
[J].
Random forests
[J].
Prediction of PM2.5 concentration level based on random forest and meteorological parameters
[J].
基于随机森林和气象参数的PM2.5浓度等级预测
[J].
Comparison of atmospheric matter and aeros optical depth in Beijing city
[J],
北京市近地层颗粒物浓度与气溶胶光学厚度相关性分析研究
[J].
Estimating PM2.5 concentrations via random forest method using satellite, auxiliary, and ground-level station dataset at multiple temp-oral scales across China in 2017
[J].
Remote sensing estimation of suspended sediment concentration based on Random Forest Regression Model
[J].
Inversion of PM2.5 concentration in Beijing based on visibility and AOD data
[J].
基于能见度及AOD数据的北京市PM2.5浓度的反演
[J].
Correlation between averaged PM2.5 concentrations and MODIS aerosol optical depth during different periods in Beijing
[J].
北京地区不同时段平均PM2.5浓度与MODIS气溶胶光学厚度相关性分析
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}