1 引 言
高光谱遥感能够获取数百个连续窄波段的光谱信息,且所获取的信息包含丰富的空间和光谱信息,成为地质制图、植被调查、城市规划、军事调查和环境监测等领域的有效技术手段[1 ,2 ,3 ] 。其中实现地物目标分类是高光谱遥感数据应用研究的主要内容[4 ] 。然而,高光谱遥感影像分类面临着一些巨大的挑战,主要是高光谱遥感影像数据量大而可利用的标签样本少。且当训练数据有限时,随着波段数目地继续增加,分类精度反而下降,即所谓的“休斯现象”[6 ] 。针对高光谱遥感影像分类面临的难题,许多经典的机器学习和数据挖掘算法应用于高光谱遥感分类中,并且取得了较好的效果,例如:支持向量机(Support Vector Machine,SVM)[5 ] 、极限学习机(Extreme Learning Machine,ELM)[7 ] 和随机森林(Random Forest,RF)[8 ] 等。近年来深度学习(Deep Learning)[9 ] 和迁移学习(Transfer Learning)等算法成为高光谱遥感影像分类的研究热点。但任何一种分类算法都不是万能的,在取得较好的分类精度的同时也都有自身的缺陷。因此,除了发展性能更先进分类器外,利用集成学习综合各分类器的优点进行图像分类也成为热点方向[10 ] 。
集成学习不是特指某种分类算法,而是集成多个基分类器共同决策的机器学习方法[11 ] 。该方法通过选择简单的分类算法,获得多个不同的基分类器,然后采用某种集成方式组合成一个强分类器,从而显著提高分类系统的泛化能力和分类精度[12 ] 。近年来,随着集成学习理论的提出与发展,基于集成学习的高光谱遥感影像分类算法引起了研究人员的广泛关注。随机森林(Random Forest,RF)是其中最具代表性的集成学习算法[14 ] 。该算法基于决策树的集合,利用Bootstrape (自助法)采样方法生成训练子集,基于训练子集训练决策树,每颗决策树投票决策出最终分类结果[15 ] 。针对高光谱遥感影像分类面临的高维灾难问题,引入子空间的概念,提出了基于随机子空间的极限学习机集成和基于旋转子空间的极限学习机等两种集成方式[16 ] 。Boosting作为一种经典的集成学习方式,通过改变训练样本的权重分布来训练基分类器并将其预测结果组合成一个强分类器。Boosting集成策略中基分类器的选取至关重要,基于AdaBoost的神经网络集成算法利用神经网络算法作为基分类器取得了不错的分类表现[17 ] 。由于ELM的高性能,Samat等[18 ] 提出的基于AdaBoost的ELM集成算法分类精度显著优于基于AdaBoost的神经网络集成方法。但基分类器ELM随机化输入权重,导致该集成算法稳定性较差。多特征的利用可以进一步提升分类效果,Chen等[19 ] 提出结合多特征和AdaBoost的算法,在集成过程中将各种类的特征赋予不同的基分类器,但是特征的种类对实验结果影响较大。Xia等[20 ] 将扩展形态学属性剖面作为空间特征,采用随机森林作为基分类器,提出了基于Boosting的随机森林集成,极大地提高了分类精度。
近年来,协同表示(Collaborative Representation, CR)以模型简单、结构稳定在高光谱遥感分类中得到越来越多的关注。协同表示认为测试样本可以由训练样本集中同类的样本子集进行线性表示,分类依据为某类训练样本子集的表示估计值与测试样本的真实值最为接近。协同表示框架中的基于切空间的协同表示算法[21 ] (Tangent Space Collaborative Representation,TCRC)利用了测试样本的简化切空间,分类精度进一步得到提升。在模式识别领域中,将多重协同表示与Boosting思想相结合的算法[22 ] 已经取得了良好的识别性能,该算法采用CR作为基分类器,分类精度提升有限。因此考虑基于Boosting原理引入分类表现较优的TCRC作为基分类器,可进一步提升高光谱遥感影像分类的准确性和可靠性。
本文提出的Boost TCRC算法为同构集成,即利用相同的分类算法TCRC作为基分类器,结合Boosting算法思想,引入训练样本权重和分类器权重,在迭代训练过程中提高错误分类样本的权重,降低正确分类样本的权重,使得下一轮的分类器更加关注被错误分类的训练样本。并且根据基分类器的分类表现赋予其投票权重,错误率低的基分类器赋予高权重,错误率高的基分类器赋予低权重,最终实现各基分类在残差域有权重的融合。
为进一步提升切空间协同表示算法的分类精度,提出基于Boosting的切空间协同表示分类集成算法,探讨Boosting集成学习方式对高光谱遥感影像分类效果的影响。并且使用HyMap和AVIRIS两个不同的传感器的高光谱遥感影像数据进行实验验证。实验证明该算法是一种有效的同构集成学习方法。
2 切空间协同表示分类与Boosting
2.1 切空间协同表示
假设X ∈ R d * M M 个训练样本的集合(d 表示波段数),其中包含K 个类别。训练样本集构造相应的字典D = D 1 , D 2 , . . . D K m 类样本构成的字典表示为D m = { x m i } i = 1 M m m ∈ { 1,2 , . . . , K } ∑ m = 1 K M m = M
α = a r g m i n α * ( y - D α * 2 2 ) + λ α * 2 2 (1)
在高光谱遥感影像分类的问题中,总是假设同一类别的样本位于同一个低维流形中。根据该假设,测试样本的光谱空间及其可能的变化空间位于同一低维流形中。因此,转换表示的形式为:
T ( y , v ) : y ∈ Μ → V y ' ∈ M (2)
其中:y y ' v y y
T ( y , v ) = T ( y , 0 ) + ∂ T ( y , v ) ∂ v v = 0 v + ο ( v 2 ) ≈ y + T ( y ) v (3)
( α , v ) = a r g m i n α , v ( y + T ( y ) v - D α 2 2 + λ α 2 2 ) (4)
其中:T ( y ) = ( ∂ T ( y , v ) / ∂ v ) v = 0 y Δ y = [ y 1 ' - y ; y 2 ' - y ; . . . y n ' - y ] n 表示为测试样本y
s p a n ( Δ y ) ≅ s p a n ( T ( y ) ) (5)
∀ v , ∃ β ⇒ T ( y ) v = Δ y β (6)
Δ y β β
( α , β ) = a r g m i n α , β ( y + Δ y β - D α 2 2 + λ α 2 2 + η β 2 2 (7)
其中:λ、η为正则化系数用于平衡惩罚项和误差项的大小。求出目标函数的最小值,求解得到α β
α = ( D T D + λ I - D T P D ) - 1 ( D T y - D T P y ) (8)
β = ( Δ y T Δ y + η I ) - 1 ( Δ y T D α - Δ y T Δ y ) (9)
其中:P = Δ y ( Δ y T Δ y + η I ) Δ y T y m 类,则测试样本y y ˜ m = D m ( D m T D m + λ I - D m T P D m ) - 1 ( D m T y - D m T P y ) y
c l a s s ( y ) = a r g m i n m = 1,2 , . . . K r m ( y ) = a r g m i n m = 1,2 . . . K ( y + Δ y β - y ˜ m 2 2 ) (10)
2.2 Boosting
集成学习通过选择结构较为简单的学习算法作为基分类器,将多个基分类器的预测结果以某种结合策略集成,从而得到分类精度高且鲁棒性强的分类器。生成基分类器的方法一般分为两大类:①将不同学习算法应用于相同的训练样本集上,即异构集成;②将同一学习算法应用于不同的训练样本集上,可以通过对训练样本进行有放回采样或者改变输入特征,即同构集成。集成学习系统有效的关键在于能否产生具有差异性强和分类性能高的基分类器。差异性要求基分类器产生的泛化误差应尽可能不相关。为了达到预设的差异性,同构集成方式中经常使用3种策略:①基于不同训练样本的构造方式,如经典的集成方式Bagging和Boosting算法;②基于不同特征集的构造方式,如随机子空间算法和旋转森林等;③基于同一分类算法的不同参数组合,多数分类器中含有参数组合,利用不同的参数组合得到不同的分类结果。
集成学习通常也称为分类器集合或者多分类器系统,它认为不同的分类器具有不同的决策性能,组合不同的分类器一起使用,可以有效提高分类系统的分类精度和泛化能力。原因是多数的分类器取得局部解,而不同的分类器从不同出发点进行局部搜索,因此集成学习更容易逼近目标函数从而达到整体最优。而且集成学习还解决了单个分类器遇到的过适应问题,不易发生对训练数据过于精细刻画的现象。集成学习通常要求基分类器的分类精度稍微高于随机猜测。Bagging集成策略要求基分类器必须是不稳定的,也就是说分类器对样本或者参数越敏感,集成效果表现越好;而Boosting算法对稳定和不稳定分类器均适用。
Freund在Boosting的基础上提出了一种改进算法-AdaBoost(Adaptive Boosting)算法。该算法具体实现步骤为,首先令所有训练样本的初始权重值均为1/N ,权重值代表被基分类器选为训练样本的概率。在之后的训练迭代过程中,若某训练样本被正确分类,权重值减小,则构造下一轮的训练样本集时,被选中的概率降低;若某训练样本被错误分类,权重值增大,则构造下一轮的训练样本集时,被选中的概率增加。因此,AdaBoost算法更关注那些较难分类的训练样本。权重更新过的训练样本集被用来训练下一个分类器。同时,在迭代训练过程中自适应地调整各基分类器的权重,决策投票时误差率大的基分类器获得低权重,而误差率小的基分类器获得高权重。最后各基分类器的预测值加权平均得到最终的集成分类结果。Bagging算法能明显减少分类的方差,而Boosting算法能同时减少分类的方差和偏差,因此大部分情况下Boosting算法要比Bagging算法准确性高,但Boosting算法对噪声十分敏感。并且当对训练数据产生过拟合现象时,Boosting算法可能会失效。AdaBoost算法的具体过程如下:
(2)输入训练样本集S = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ ( x N , y N ) } N 表示训练样本总数,y i y i ∈ - 1 , + 1 T 。
(3)对训练集S的样本权值分布D i D 1 D 1 ( i ) = 1 / N , i = 1,2 , ⋯ , N
(a)根据训练样本权值分布D t S t S t h t ( x ) h t ( x ) ε t
ε t = ∑ i = 1 m D t . * E E ( i ) = 0 , h t ( x i ) = y i 1 , h t ( x i ) ≠ y i
α t = 1 2 l o g ( 1 - ε t ε t )
(c)更新训练样本权值D t + 1 = D t ( i ) e x p ( - α t y i h t ( x i ) ) Z t Z t D t + 1
(5)输出强分类器H ( x ) = s i g n ( ∑ t = 1 T α t h t ( x ) ) H (x)表示分类器组合模型,sign(.)为符号函数,取值为1或⁃1。
3 基于Boosting的切空间协同表示集成学习方法
训练样本的权重描述了训练样本对于测试样本分类的贡献率。每个训练样本重要性不同,提出的Boost TCRC算法可以重新平衡每个训练样本在每类中的重要性。在每次迭代训练过程中,根据分类器的当前错误率调整每个训练样本的权值,降低正确分类的训练数据的概率,增加错误分类的训练数据的概率。通过这种方式,Boost TCRC算法专注于信息量大或分类难度较大的训练样本。同时该算法自适应地降低错误分类率较大的基分类器TCRC的权重和增加错误分类率较小的基分类器TCRC的权重。迭代结束后,根据Boost TCRC算法,测试样本y
c l a s s ( y ) = a r g m i n m = 1,2 . . . K r m ( y )
其中:r m ( y ) = ∑ t = 1 T ∂ t y + Δ y β t - D m t α m t 2 2 T 个基分类器TCRC的权重系数为∂ = [ ∂ 1 , . . . , ∂ T ] ∑ t = 1 T ∂ t = 1 ∂ 值越大,赋予基分类器的权重越大,而当∂ t = 0 d t d t ( i ) < 0 i 个训练样本分类正确,d t ( i ) i 个样本的可区分性更强。若d t ( i ) > 0 i 个训练样本分类错误,d t ( i ) i 个样本错分程度越明显。d t X t ε t ε t < b t
(1)输入:基分类器TCRC,训练集X ∈ R d * M y Δ y Δ X T
(2)对训练集X D i D 1 D 1 ( i ) = 1 / M , i = 1,2 , . . . , M
(a)根据训练样本权值分布D t t 个训练集X t X t D t
(b)根据公式(8)和(9)计算d t ( i ) = X + Δ X β t - D c t α c t 2 2 - m i n m ≠ c X + Δ X β t - D m t α m t 2 2
(c)计算ε t = d o t ( D t , d t ) b t = m a x d t
(d)计算测试样本y r m ( y ) = y + Δ y β t - D m t α m t 2 2 m = 1,2 , ⋯ , K
(e)计算基分类器权重∂ t = m a x 1 2 b t l o g b t - ε t b t + ε t , 0
(f)更新训练样本的权重D t + 1 ( i ) = D t ( i ) Z t e ∂ t d t Z t D t + 1
(4) 输出基分类器的归一化后权重∂ t t = 1 T y
c l a s s ( y ) = a r g m i n m = 1,2 . . . K ∑ t = 1 T ∂ t y + Δ y β t - D m t α m t 2 2
4 实验与分析
4.1 实验数据
实验数据一是普度大学(Purdue Campus)西拉斐特分校校区,该数据于1999年9月30日通过机载高光谱制图仪(Hyperspectral Mapper,HYMAP)系统采集,在可见光和红外区域(400~2 400 nm)涵盖128条光谱波段。实验中剔除水吸收波段后保留126条波段,空间分辨率为3.5 m。该实验数据大小为377像素×512像素,共包含6类地物,分别为道路、草地、阴影、土壤、树木和建筑物。该高光谱数据假彩色图如图1 (a)所示,样本分布如图1 (b)所示。标记样本被随机分成训练样本和测试样本,共选取了90个训练样本,平均每类地物20个训练样本。
图1
图1
Purdue Campus 数据集
Fig.1
Purdue Campus data set
实验数据二是美国印第安纳州Indian Pines实验区,采用的是机载可见光红外成像光谱仪(Airborne Visible Infrared Imaging Spectrometer,AVIRIS)采集,包括从可见光到近红外(400~2 450 nm)的220个波段的光谱数据,剔除水吸收后保留200个光谱波段,空间分辨率约为20 m。该实验数据大小为145像素×145像素,共包括16类地物类型,为取得足够的训练样本去除7类地物,剩余的9类用于实验分析。该高光谱数据的假彩色图像如图2 (a)所示,样本分布如图2 (b)所示。实验根据样本分布图共随机选取466个像元作为训练样本,平均每类约占5%,其余像元作为测试样本进行精度评定。
图2
图2
Purdue Campus数据集6种分类算法的分类效果图
Fig.2
Classification maps of Purdue Campus using six algorithms
4.2 实验设置
为验证Boost TCRC算法的有效性,采用Purdue Campus 高光谱影像数据和Indian Pines 高光谱影像数据进行实验。两组实验采用Boosting、随机森林(Random Forest)、ELM、AdaBoost ELM和TCRC 分类器等作为对比算法,其中Boosting算法中基分类器为决策树,规模为20棵,随机森林算法中决策树规模为20棵。随机森林算法采用Bootstrap采样方法,对原始样本进行有放回的随机抽样,获得与原始训练样本集同等样本数量的训练样本子集。AdaBoost ELM算法为Samat等提出一种集成算法,该算法结合基分类器ELM算法和AdaBoost集成方式。两组数据中ELM算法和AdaBoost ELM算法均设置了最佳的隐含层神经元个数。分类性能评价指标包括总体分类精度(Overall Accuracy,OA)、平均分类精度(Average Accuracy,AA)和Kappa系数。表1 中详细列出了两个数据集中算法的最优参数,T 代表集成次数,n 的值表示相邻像素的数量,λ和η为Boost TCRC和TCRC算法中的正则化参数。六种方法重复10次实验取平均值,参数设置采用交叉验证的方法。
4.3 实验结果与分析
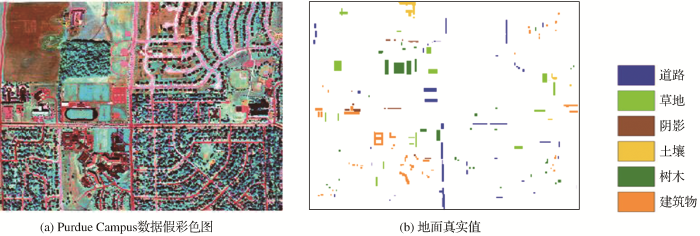
图3 显示了第一组实验数据6种算法的分类结果图。不难发现,Boost TCRC分类器分类效果最好,AdaBoost ELM分类器次之,Boosting分类器效果最差。Boost TCRC算法中T 设置为20次,AdaBoost ELM算法中T 也设置为20次。表2 中6种分类器(Boosting、RF、ELM、TCRC、AdaBoost ELM和Boots TCRC)的OA(%)值分别为86.09、87.31、89.36、90.91、91.92和93.73。可以看出,Boost TCRC算法总体分类精度、平均分类精度和Kappa系数比基分类器TCRC分别提高了2.82%、2.01%和0.032,体现了Boosting集成方式的优越性和有效性。AdaBoost ELM分类算法总体精度也比基分类器ELM算法提升了约2.5%,但提升的幅度略低于Boost TCRC集成算法。RF总体分类精度为87.31%,比AdaBoost ELM算法和Boost TCRC算法总体分类精度分别低了4.61%和6.42%。Boosting 算法总体分类精度最低,仅为86.09%。Boost TCRC分类器在6种算法中总体精度和平均精度均取得最佳的实验结果,其次是AdaBoost ELM分类器和TCRC分类器。
图3
图3
Indian Pines数据集
Fig.3
Indian Pines data set
第二组实验数据6种分类算法的分类结果如图4 所示。Boost TCRC算法的分类结果比TCRC算法的分类结果更准确。由于利用邻域信息,Boost TCRC算法的分类图比AdaBoost ELM算法的分类图更平滑。如表3 所示,6种分类器(Boosting、RF、ELM、TCRC、AdaBoost ELM和Boots TCRC)的OA(%)值分别为69.48、71.05、71.15、80.14、72.09和84.11。Boost TCRC算法的分类性能均显著优于其他分类器,其中Boost TCRC算法总体分类精度、平均分类精度和Kappa系数相比较于TCRC算法分别提高了约4%、0.9%和0.049 2,充分证明了集成学习的有效性。基分类ELM算法总体分类精度为71.51%,所以AdaBoost ELM集成算法分类精度有限,约为72.09%。随机森林总体分类精度为71.05%,比Boost TCRC算法的总体分类精度低了约13%。
图4
图4
Indian Pines数据集6种算法的分类效果图
Fig.4
Classification maps of Indian Pines using six algorithms
值得注意的是,Boost TCRC分类器的总体精度高于AdaBoost ELM分类器约12%,高于Boosting分类器约14.63%,说明基分类器对集成的效果影响较大。
4.4 参数分析
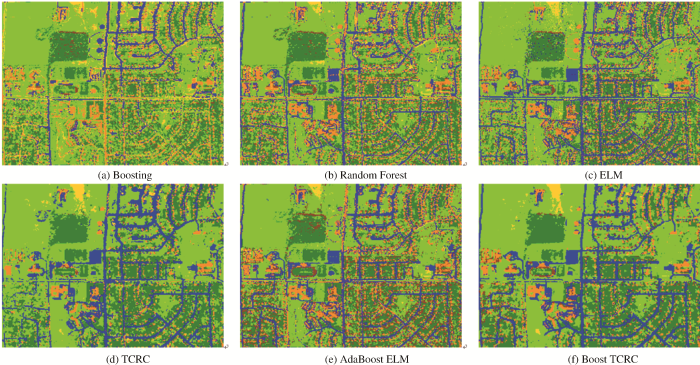
图5 对应AdaBoost ELM和Boost TCRC两种集成算法的总体分类精度值随集成次数T 的变化。实验过程中T 值分别设置为10、20、40和60。图5 中X坐标轴的零值代表分别两种集成算法的基分类器(TCRC,ELM)的总体分类精度值。从图5 (a)中可发现,对于HyMap数据,Boost TCRC分类器总体分类精度随T 值增加而增大,当T 值设置为60次时,总体分类精度达到约94%。比TCRC算法总体分类精度提升了约3%。值得注意的是,当Indian Pines数据集中T 值设置大于10次时,Boost TCRC 算法的分类表现反而越来越差。可能的原因是Indian Pines数据分辨率不高,噪声较多,发生了Boost TCRC算法对训练数据过度拟合的现象。总体而言,对于两组数据,当T 值为10次到20次左右时,Boost TCRC算法总体精度得到明显提高,且算法分类表现优于AdaBoost ELM算法。
图5
图5
两组数据不同T 值下算法的分类结果
Fig.5
Overall accuracy of different algorithms for two data set with varying T
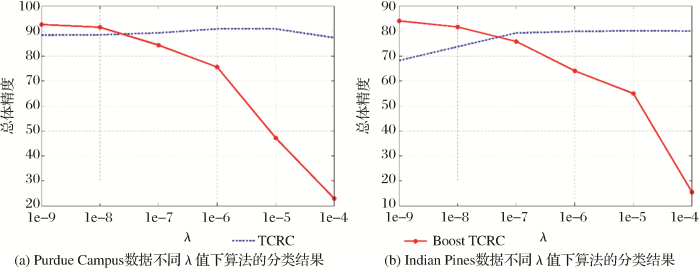
Boost TCRC算法中受正则化参数影响较大,该算法存在两个正则化参数,分别为λ和η。实验中参数λ设置的范围为1e-9~1e-4。为了方便实施实验,T 设定为10次。AVIRIS数据集中Boost TCRC和TCRC两种算法最佳参数设置均为η=1e-8和n =8。参数λ变化趋势如图6 (b)所示,可以看出Boost TCRC算法对正则化参数λ的敏感性明显高于TCRC算法。当λ=1e-4时,Boost TCRC算法的总体精度甚至下降到17%。对于Purdue Campus数据集,Boost TCRC和TCRC两算法最佳参数设置为η=1e-8和n =8。参数λ的变化趋势如图6 (a)所示。和AVIRIS数据类似,Boost TCRC算法也会随着λ的增加出现分类精度骤降的现象。
图6
图6
两组数据不同λ值下算法的分类结果
Fig.6
Overall accuracy of different algorithms for two data sets with varying λ
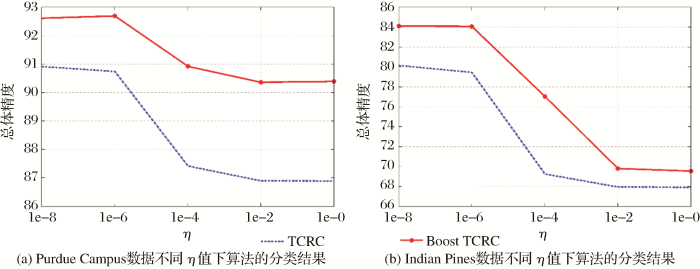
图7 分析了两组高光谱数据中Boost TCRC和TCRC两种算法的总体分类精度值与正则化参数η之间的变化关系。实验中设置η范围为1e-8~1e-0,T 也设定为10次。针对HyMap数据,Boost TCRC算法最佳参数设置为λ=1e-9,n =8,TCRC算法最佳参数设置为λ=1e-6,n =8。从图7 (a)中可得,Boost TCRC算法的性能优于TCRC算法且两种算法均存在随着正则化参数η增加分类精度随之下降的趋势。AVIRIS数据中Boost TCRC算法最佳参数设置为λ=1e-9,n =8,TCRC算法最佳参数设置为λ=1e-4,n =8。与HyMap数据类似,Boost TCRC算法分类精度高于TCRC算法,体现出了集成学习的优越性能。
图7
图7
两组数据不同η值下算法的分类结果
Fig.7
Overall accuracy of different algorithms for two data sets with varying η
为了进一步比较不同算法的时间复杂度,在表2 和表3 中记录了两组实验数据中6种算法的运行时间(仅分类过程,运行10次的平均时间)。实验基于2.8.GHz CPU和8G内存的计算机,所有实验均在Matlab软件中进行。本文对比的几种集成算法中,随机森林算法运算速率最快,AdaBoost ELM算法次之, Boosting 算法运算速率最慢。与TCRC算法相比,由于串行生成基学习器,Boost TCRC算法导致了运算复杂度增加和运算效率的降低,耗时最多。但AdaBoost ELM 集成算法采用运算速率快的基分类器ELM,所以较Boost TCRC算法耗时少。
5 结 语
为进一步提升高光谱遥感影像的分类效果,本文提出了基于Boosting的切空间协同表示高光谱遥感影像集成分类算法。该方法利用TCRC作为基分类器进行预测,自适应地学习基分类器TCRC和训练样本的权重,使得分类器专注于信息量较大或较难分类的训练样本,最终各基分类器在残差域实现有权重的融合。
采用两组高光谱影像数据进行实验验证,结果表明:①HyMap影像数据Boost TCRC算法的总体精度比TCRC算法提高了约3%,而在AVIRIS数据中总体精度提升了约4%。虽然两组数据Boost TCRC算法提升幅度不同,但均优于基分类器TCRC和AdaBoost ELM集成算法;②两组数据Boost TCRC算法的分类精度随着集成次数的增加呈现出不同趋势,但都能获得高于TCRC算法的分类精度。
本文算法虽在一定程度上提升了TCRC算法的分类效果,也存在一些不足之处,如Boost TCRC算法对正则化参数λ十分敏感,随着λ的增加会出现分类精度骤减的现象;而且迭代训练过程会不可避免地导致计算复杂度高和计算效率下降的问题。因此该算法如何减小计算复杂度有待进一步研究。
参考文献
View Option
[1]
Tong Qingxi Zhang Bing Zheng Lanfen Hyperspectral Remote Sensing [M]. Beijing : Higher Education Press ,2006 .
[本文引用: 1]
童庆禧 ,张兵 ,郑兰芬 高光谱遥感 [M].北京 :高等教育出版社 ,2006 .
[本文引用: 1]
[2]
Landgrebe D Hyperspectral Image Data Analysis
[J]. IEEE Signal Processing Magazine , 2002 , 19 (1 ):17 -28 .
[本文引用: 1]
[3]
Moon H Ahn H Kodell R L et al Ensemble Methods for Classification of Patients for Personalized Medicine with High-dimensional Data
[J]. Artificial Intelligence in Medicine , 2007 , 41 (3 ):197 -207 .
[本文引用: 1]
[4]
Bioucas-Dias J M Plaza A Camps-Valls G et al Hyperspectral Remote Sensing Data Analysis and Future Challenges
[J]. IEEE Geoscience and Remote Sensing Magazine , 2013 , 1 (2 ):6 -36 .
[本文引用: 1]
[5]
Dozier J Painter T H Multispectral and Hyperspectral Remote Sensing of Alpine Snow Properties
[J]. Annual Review Earth Planetary , Sciences , 2004 , 32 : 465 -494 .
[本文引用: 1]
[6]
Braun A C Weidner U Hinz S Classification in High-dimensional Feature Spaces-assessment Using SVM, IVM and RVM with Focus on Simulated EnMAP Data
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2012 , 5 (2 ):436 -443 .
[本文引用: 1]
[7]
Chen C Li W Su H et al Spectral-spatial Classification of Hyperspectral Image based on Kernel Extreme Learning Machine
[J]. Remote Sensing , 2014 , 6 (6 ): 5795 -5814 .doi: 10.3390/rs6065795 .
[本文引用: 1]
[8]
Zhang Y Cao G Li X et al Cascaded Random Forest for Hyperspectral Image Classification
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2018 ,11 (4 ):1082 -1094 .
[本文引用: 1]
[9]
Li S Song W Fang L et al Deep Learning for Hyperspectral Image Classification:An Overview
[J].IEEE Transactions on Geoscience and Remote Sensing , 2019 , 57 (9 ):6690 -6709 .
[本文引用: 1]
[10]
Zhang H Li Y Jiang Y et al Hyperspectral Classification based on Lightweight 3-D-CNN With Transfer Learning
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2019 , 57 (8 ): 5813 -5828 .
[本文引用: 1]
[11]
Chen Y Wang Y Gu Y et al Deep Learning Ensemble for Hyperspectral Image Classification
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2019 , 12 (6 ): 1882 -1897 .
[本文引用: 1]
[12]
Bao R Xia J Mura M D et al Combining Morphological Attribute Profiles via an Ensemble Method for Hyperspectral Image Classification
[J]. IEEE Geoscience and Remote Sensing Letters , 2016 , 13 (3 ): 359 -363 .
[本文引用: 1]
[13]
Benediktsson J A Chanussot J Fauvel M Multiple Classifier Systems in Remote Sensing: from Basics to Recent Developments
[C]//International Workshop on Multiple Classifier Systems . Springer, Berlin, Heidelberg , 2007 : 501 -512 .
[14]
Chan J C W Paelinckx D Evaluation of Random Forest and Adaboost Tree-based Ensemble Classification and Spectral Band Selection for Ecotope Mapping Using Airborne Hyperspectral Imagery
[J]. Remote Sensing of Environment , 2008 , 112 (6 ): 2999 -3011 .doi: 10.1016/j.rse.2008.02.011 .
[本文引用: 1]
[15]
Gislason P O Benediktsson J A Sveinsson J R Random Forests for Land Cover Classification
[J]. Pattern Recognition Letters , 2006 , 27 (4 ): 294 -300 .
[本文引用: 1]
[16]
Xia J Dalla Mura M Chanussot J et al Random Subspace Ensembles for Hyperspectral Image Classification with Extended Morphological Attribute Profiles
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2015 , 53 (9 ): 4768 -4786 .
[本文引用: 1]
[17]
Haq Q S U Tao L Yang S Neural Network based Adaboosting Approach for Hyperspectral Data Classification
[C]// IEEE International Conference on Computer Science & Network Technology , 2012 .
[本文引用: 1]
[18]
Samat A Du P Liu S et al ELM2 : Ensemble Extreme Learning Machines for Hyperspectral Image Classification
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2014 , 7 (4 ): 1060 -1069 .
[本文引用: 1]
[19]
Chen Y Zhao X Lin Z Joint Adaboost and Multifeature based Ensemble for Hyperspectral Image Classification
[C]//2014 IEEE Geoscience and Remote Sensing Symposium , 2014 : 2874 -2877 .
[本文引用: 1]
[20]
Xia J Ghamisi P Yokoya N et al Random Forest Ensembles and Extended Multiextinction Profiles for Hyperspectral Image Classification
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2018 , 56 (1 ): 202 -216 .
[本文引用: 1]
[21]
Su H Bo Z Qian D et al Tangent Distance-based Collaborative Representation for Hyperspectral Image Classification
[J]. IEEE Geoscience and Remote Sensing Letters , 2016 , 13 (9 ):1236 -1240 .
[本文引用: 1]
[22]
Chi Y Porikli F Classification and Boosting with Multiple Collaborative Representations
[J].IEEE Transactions on Pattern Analysis and Machine Intelligence ,2014 ,36 (8 ):1519 -1531 .
[本文引用: 1]
1
2006
... 高光谱遥感能够获取数百个连续窄波段的光谱信息,且所获取的信息包含丰富的空间和光谱信息,成为地质制图、植被调查、城市规划、军事调查和环境监测等领域的有效技术手段[1 ,2 ,3 ] .其中实现地物目标分类是高光谱遥感数据应用研究的主要内容[4 ] .然而,高光谱遥感影像分类面临着一些巨大的挑战,主要是高光谱遥感影像数据量大而可利用的标签样本少.且当训练数据有限时,随着波段数目地继续增加,分类精度反而下降,即所谓的“休斯现象”[6 ] .针对高光谱遥感影像分类面临的难题,许多经典的机器学习和数据挖掘算法应用于高光谱遥感分类中,并且取得了较好的效果,例如:支持向量机(Support Vector Machine,SVM)[5 ] 、极限学习机(Extreme Learning Machine,ELM)[7 ] 和随机森林(Random Forest,RF)[8 ] 等.近年来深度学习(Deep Learning)[9 ] 和迁移学习(Transfer Learning)等算法成为高光谱遥感影像分类的研究热点.但任何一种分类算法都不是万能的,在取得较好的分类精度的同时也都有自身的缺陷.因此,除了发展性能更先进分类器外,利用集成学习综合各分类器的优点进行图像分类也成为热点方向[10 ] . ...
1
2006
... 高光谱遥感能够获取数百个连续窄波段的光谱信息,且所获取的信息包含丰富的空间和光谱信息,成为地质制图、植被调查、城市规划、军事调查和环境监测等领域的有效技术手段[1 ,2 ,3 ] .其中实现地物目标分类是高光谱遥感数据应用研究的主要内容[4 ] .然而,高光谱遥感影像分类面临着一些巨大的挑战,主要是高光谱遥感影像数据量大而可利用的标签样本少.且当训练数据有限时,随着波段数目地继续增加,分类精度反而下降,即所谓的“休斯现象”[6 ] .针对高光谱遥感影像分类面临的难题,许多经典的机器学习和数据挖掘算法应用于高光谱遥感分类中,并且取得了较好的效果,例如:支持向量机(Support Vector Machine,SVM)[5 ] 、极限学习机(Extreme Learning Machine,ELM)[7 ] 和随机森林(Random Forest,RF)[8 ] 等.近年来深度学习(Deep Learning)[9 ] 和迁移学习(Transfer Learning)等算法成为高光谱遥感影像分类的研究热点.但任何一种分类算法都不是万能的,在取得较好的分类精度的同时也都有自身的缺陷.因此,除了发展性能更先进分类器外,利用集成学习综合各分类器的优点进行图像分类也成为热点方向[10 ] . ...
Hyperspectral Image Data Analysis
1
2002
... 高光谱遥感能够获取数百个连续窄波段的光谱信息,且所获取的信息包含丰富的空间和光谱信息,成为地质制图、植被调查、城市规划、军事调查和环境监测等领域的有效技术手段[1 ,2 ,3 ] .其中实现地物目标分类是高光谱遥感数据应用研究的主要内容[4 ] .然而,高光谱遥感影像分类面临着一些巨大的挑战,主要是高光谱遥感影像数据量大而可利用的标签样本少.且当训练数据有限时,随着波段数目地继续增加,分类精度反而下降,即所谓的“休斯现象”[6 ] .针对高光谱遥感影像分类面临的难题,许多经典的机器学习和数据挖掘算法应用于高光谱遥感分类中,并且取得了较好的效果,例如:支持向量机(Support Vector Machine,SVM)[5 ] 、极限学习机(Extreme Learning Machine,ELM)[7 ] 和随机森林(Random Forest,RF)[8 ] 等.近年来深度学习(Deep Learning)[9 ] 和迁移学习(Transfer Learning)等算法成为高光谱遥感影像分类的研究热点.但任何一种分类算法都不是万能的,在取得较好的分类精度的同时也都有自身的缺陷.因此,除了发展性能更先进分类器外,利用集成学习综合各分类器的优点进行图像分类也成为热点方向[10 ] . ...
Ensemble Methods for Classification of Patients for Personalized Medicine with High-dimensional Data
1
2007
... 高光谱遥感能够获取数百个连续窄波段的光谱信息,且所获取的信息包含丰富的空间和光谱信息,成为地质制图、植被调查、城市规划、军事调查和环境监测等领域的有效技术手段[1 ,2 ,3 ] .其中实现地物目标分类是高光谱遥感数据应用研究的主要内容[4 ] .然而,高光谱遥感影像分类面临着一些巨大的挑战,主要是高光谱遥感影像数据量大而可利用的标签样本少.且当训练数据有限时,随着波段数目地继续增加,分类精度反而下降,即所谓的“休斯现象”[6 ] .针对高光谱遥感影像分类面临的难题,许多经典的机器学习和数据挖掘算法应用于高光谱遥感分类中,并且取得了较好的效果,例如:支持向量机(Support Vector Machine,SVM)[5 ] 、极限学习机(Extreme Learning Machine,ELM)[7 ] 和随机森林(Random Forest,RF)[8 ] 等.近年来深度学习(Deep Learning)[9 ] 和迁移学习(Transfer Learning)等算法成为高光谱遥感影像分类的研究热点.但任何一种分类算法都不是万能的,在取得较好的分类精度的同时也都有自身的缺陷.因此,除了发展性能更先进分类器外,利用集成学习综合各分类器的优点进行图像分类也成为热点方向[10 ] . ...
Hyperspectral Remote Sensing Data Analysis and Future Challenges
1
2013
... 高光谱遥感能够获取数百个连续窄波段的光谱信息,且所获取的信息包含丰富的空间和光谱信息,成为地质制图、植被调查、城市规划、军事调查和环境监测等领域的有效技术手段[1 ,2 ,3 ] .其中实现地物目标分类是高光谱遥感数据应用研究的主要内容[4 ] .然而,高光谱遥感影像分类面临着一些巨大的挑战,主要是高光谱遥感影像数据量大而可利用的标签样本少.且当训练数据有限时,随着波段数目地继续增加,分类精度反而下降,即所谓的“休斯现象”[6 ] .针对高光谱遥感影像分类面临的难题,许多经典的机器学习和数据挖掘算法应用于高光谱遥感分类中,并且取得了较好的效果,例如:支持向量机(Support Vector Machine,SVM)[5 ] 、极限学习机(Extreme Learning Machine,ELM)[7 ] 和随机森林(Random Forest,RF)[8 ] 等.近年来深度学习(Deep Learning)[9 ] 和迁移学习(Transfer Learning)等算法成为高光谱遥感影像分类的研究热点.但任何一种分类算法都不是万能的,在取得较好的分类精度的同时也都有自身的缺陷.因此,除了发展性能更先进分类器外,利用集成学习综合各分类器的优点进行图像分类也成为热点方向[10 ] . ...
Multispectral and Hyperspectral Remote Sensing of Alpine Snow Properties
1
2004
... 高光谱遥感能够获取数百个连续窄波段的光谱信息,且所获取的信息包含丰富的空间和光谱信息,成为地质制图、植被调查、城市规划、军事调查和环境监测等领域的有效技术手段[1 ,2 ,3 ] .其中实现地物目标分类是高光谱遥感数据应用研究的主要内容[4 ] .然而,高光谱遥感影像分类面临着一些巨大的挑战,主要是高光谱遥感影像数据量大而可利用的标签样本少.且当训练数据有限时,随着波段数目地继续增加,分类精度反而下降,即所谓的“休斯现象”[6 ] .针对高光谱遥感影像分类面临的难题,许多经典的机器学习和数据挖掘算法应用于高光谱遥感分类中,并且取得了较好的效果,例如:支持向量机(Support Vector Machine,SVM)[5 ] 、极限学习机(Extreme Learning Machine,ELM)[7 ] 和随机森林(Random Forest,RF)[8 ] 等.近年来深度学习(Deep Learning)[9 ] 和迁移学习(Transfer Learning)等算法成为高光谱遥感影像分类的研究热点.但任何一种分类算法都不是万能的,在取得较好的分类精度的同时也都有自身的缺陷.因此,除了发展性能更先进分类器外,利用集成学习综合各分类器的优点进行图像分类也成为热点方向[10 ] . ...
Classification in High-dimensional Feature Spaces-assessment Using SVM, IVM and RVM with Focus on Simulated EnMAP Data
1
2012
... 高光谱遥感能够获取数百个连续窄波段的光谱信息,且所获取的信息包含丰富的空间和光谱信息,成为地质制图、植被调查、城市规划、军事调查和环境监测等领域的有效技术手段[1 ,2 ,3 ] .其中实现地物目标分类是高光谱遥感数据应用研究的主要内容[4 ] .然而,高光谱遥感影像分类面临着一些巨大的挑战,主要是高光谱遥感影像数据量大而可利用的标签样本少.且当训练数据有限时,随着波段数目地继续增加,分类精度反而下降,即所谓的“休斯现象”[6 ] .针对高光谱遥感影像分类面临的难题,许多经典的机器学习和数据挖掘算法应用于高光谱遥感分类中,并且取得了较好的效果,例如:支持向量机(Support Vector Machine,SVM)[5 ] 、极限学习机(Extreme Learning Machine,ELM)[7 ] 和随机森林(Random Forest,RF)[8 ] 等.近年来深度学习(Deep Learning)[9 ] 和迁移学习(Transfer Learning)等算法成为高光谱遥感影像分类的研究热点.但任何一种分类算法都不是万能的,在取得较好的分类精度的同时也都有自身的缺陷.因此,除了发展性能更先进分类器外,利用集成学习综合各分类器的优点进行图像分类也成为热点方向[10 ] . ...
Spectral-spatial Classification of Hyperspectral Image based on Kernel Extreme Learning Machine
1
2014
... 高光谱遥感能够获取数百个连续窄波段的光谱信息,且所获取的信息包含丰富的空间和光谱信息,成为地质制图、植被调查、城市规划、军事调查和环境监测等领域的有效技术手段[1 ,2 ,3 ] .其中实现地物目标分类是高光谱遥感数据应用研究的主要内容[4 ] .然而,高光谱遥感影像分类面临着一些巨大的挑战,主要是高光谱遥感影像数据量大而可利用的标签样本少.且当训练数据有限时,随着波段数目地继续增加,分类精度反而下降,即所谓的“休斯现象”[6 ] .针对高光谱遥感影像分类面临的难题,许多经典的机器学习和数据挖掘算法应用于高光谱遥感分类中,并且取得了较好的效果,例如:支持向量机(Support Vector Machine,SVM)[5 ] 、极限学习机(Extreme Learning Machine,ELM)[7 ] 和随机森林(Random Forest,RF)[8 ] 等.近年来深度学习(Deep Learning)[9 ] 和迁移学习(Transfer Learning)等算法成为高光谱遥感影像分类的研究热点.但任何一种分类算法都不是万能的,在取得较好的分类精度的同时也都有自身的缺陷.因此,除了发展性能更先进分类器外,利用集成学习综合各分类器的优点进行图像分类也成为热点方向[10 ] . ...
Cascaded Random Forest for Hyperspectral Image Classification
1
2018
... 高光谱遥感能够获取数百个连续窄波段的光谱信息,且所获取的信息包含丰富的空间和光谱信息,成为地质制图、植被调查、城市规划、军事调查和环境监测等领域的有效技术手段[1 ,2 ,3 ] .其中实现地物目标分类是高光谱遥感数据应用研究的主要内容[4 ] .然而,高光谱遥感影像分类面临着一些巨大的挑战,主要是高光谱遥感影像数据量大而可利用的标签样本少.且当训练数据有限时,随着波段数目地继续增加,分类精度反而下降,即所谓的“休斯现象”[6 ] .针对高光谱遥感影像分类面临的难题,许多经典的机器学习和数据挖掘算法应用于高光谱遥感分类中,并且取得了较好的效果,例如:支持向量机(Support Vector Machine,SVM)[5 ] 、极限学习机(Extreme Learning Machine,ELM)[7 ] 和随机森林(Random Forest,RF)[8 ] 等.近年来深度学习(Deep Learning)[9 ] 和迁移学习(Transfer Learning)等算法成为高光谱遥感影像分类的研究热点.但任何一种分类算法都不是万能的,在取得较好的分类精度的同时也都有自身的缺陷.因此,除了发展性能更先进分类器外,利用集成学习综合各分类器的优点进行图像分类也成为热点方向[10 ] . ...
Deep Learning for Hyperspectral Image Classification:An Overview
1
2019
... 高光谱遥感能够获取数百个连续窄波段的光谱信息,且所获取的信息包含丰富的空间和光谱信息,成为地质制图、植被调查、城市规划、军事调查和环境监测等领域的有效技术手段[1 ,2 ,3 ] .其中实现地物目标分类是高光谱遥感数据应用研究的主要内容[4 ] .然而,高光谱遥感影像分类面临着一些巨大的挑战,主要是高光谱遥感影像数据量大而可利用的标签样本少.且当训练数据有限时,随着波段数目地继续增加,分类精度反而下降,即所谓的“休斯现象”[6 ] .针对高光谱遥感影像分类面临的难题,许多经典的机器学习和数据挖掘算法应用于高光谱遥感分类中,并且取得了较好的效果,例如:支持向量机(Support Vector Machine,SVM)[5 ] 、极限学习机(Extreme Learning Machine,ELM)[7 ] 和随机森林(Random Forest,RF)[8 ] 等.近年来深度学习(Deep Learning)[9 ] 和迁移学习(Transfer Learning)等算法成为高光谱遥感影像分类的研究热点.但任何一种分类算法都不是万能的,在取得较好的分类精度的同时也都有自身的缺陷.因此,除了发展性能更先进分类器外,利用集成学习综合各分类器的优点进行图像分类也成为热点方向[10 ] . ...
Hyperspectral Classification based on Lightweight 3-D-CNN With Transfer Learning
1
2019
... 高光谱遥感能够获取数百个连续窄波段的光谱信息,且所获取的信息包含丰富的空间和光谱信息,成为地质制图、植被调查、城市规划、军事调查和环境监测等领域的有效技术手段[1 ,2 ,3 ] .其中实现地物目标分类是高光谱遥感数据应用研究的主要内容[4 ] .然而,高光谱遥感影像分类面临着一些巨大的挑战,主要是高光谱遥感影像数据量大而可利用的标签样本少.且当训练数据有限时,随着波段数目地继续增加,分类精度反而下降,即所谓的“休斯现象”[6 ] .针对高光谱遥感影像分类面临的难题,许多经典的机器学习和数据挖掘算法应用于高光谱遥感分类中,并且取得了较好的效果,例如:支持向量机(Support Vector Machine,SVM)[5 ] 、极限学习机(Extreme Learning Machine,ELM)[7 ] 和随机森林(Random Forest,RF)[8 ] 等.近年来深度学习(Deep Learning)[9 ] 和迁移学习(Transfer Learning)等算法成为高光谱遥感影像分类的研究热点.但任何一种分类算法都不是万能的,在取得较好的分类精度的同时也都有自身的缺陷.因此,除了发展性能更先进分类器外,利用集成学习综合各分类器的优点进行图像分类也成为热点方向[10 ] . ...
Deep Learning Ensemble for Hyperspectral Image Classification
1
2019
... 集成学习不是特指某种分类算法,而是集成多个基分类器共同决策的机器学习方法[11 ] .该方法通过选择简单的分类算法,获得多个不同的基分类器,然后采用某种集成方式组合成一个强分类器,从而显著提高分类系统的泛化能力和分类精度[12 ] .近年来,随着集成学习理论的提出与发展,基于集成学习的高光谱遥感影像分类算法引起了研究人员的广泛关注.随机森林(Random Forest,RF)是其中最具代表性的集成学习算法[14 ] .该算法基于决策树的集合,利用Bootstrape (自助法)采样方法生成训练子集,基于训练子集训练决策树,每颗决策树投票决策出最终分类结果[15 ] .针对高光谱遥感影像分类面临的高维灾难问题,引入子空间的概念,提出了基于随机子空间的极限学习机集成和基于旋转子空间的极限学习机等两种集成方式[16 ] .Boosting作为一种经典的集成学习方式,通过改变训练样本的权重分布来训练基分类器并将其预测结果组合成一个强分类器.Boosting集成策略中基分类器的选取至关重要,基于AdaBoost的神经网络集成算法利用神经网络算法作为基分类器取得了不错的分类表现[17 ] .由于ELM的高性能,Samat等[18 ] 提出的基于AdaBoost的ELM集成算法分类精度显著优于基于AdaBoost的神经网络集成方法.但基分类器ELM随机化输入权重,导致该集成算法稳定性较差.多特征的利用可以进一步提升分类效果,Chen等[19 ] 提出结合多特征和AdaBoost的算法,在集成过程中将各种类的特征赋予不同的基分类器,但是特征的种类对实验结果影响较大.Xia等[20 ] 将扩展形态学属性剖面作为空间特征,采用随机森林作为基分类器,提出了基于Boosting的随机森林集成,极大地提高了分类精度. ...
Combining Morphological Attribute Profiles via an Ensemble Method for Hyperspectral Image Classification
1
2016
... 集成学习不是特指某种分类算法,而是集成多个基分类器共同决策的机器学习方法[11 ] .该方法通过选择简单的分类算法,获得多个不同的基分类器,然后采用某种集成方式组合成一个强分类器,从而显著提高分类系统的泛化能力和分类精度[12 ] .近年来,随着集成学习理论的提出与发展,基于集成学习的高光谱遥感影像分类算法引起了研究人员的广泛关注.随机森林(Random Forest,RF)是其中最具代表性的集成学习算法[14 ] .该算法基于决策树的集合,利用Bootstrape (自助法)采样方法生成训练子集,基于训练子集训练决策树,每颗决策树投票决策出最终分类结果[15 ] .针对高光谱遥感影像分类面临的高维灾难问题,引入子空间的概念,提出了基于随机子空间的极限学习机集成和基于旋转子空间的极限学习机等两种集成方式[16 ] .Boosting作为一种经典的集成学习方式,通过改变训练样本的权重分布来训练基分类器并将其预测结果组合成一个强分类器.Boosting集成策略中基分类器的选取至关重要,基于AdaBoost的神经网络集成算法利用神经网络算法作为基分类器取得了不错的分类表现[17 ] .由于ELM的高性能,Samat等[18 ] 提出的基于AdaBoost的ELM集成算法分类精度显著优于基于AdaBoost的神经网络集成方法.但基分类器ELM随机化输入权重,导致该集成算法稳定性较差.多特征的利用可以进一步提升分类效果,Chen等[19 ] 提出结合多特征和AdaBoost的算法,在集成过程中将各种类的特征赋予不同的基分类器,但是特征的种类对实验结果影响较大.Xia等[20 ] 将扩展形态学属性剖面作为空间特征,采用随机森林作为基分类器,提出了基于Boosting的随机森林集成,极大地提高了分类精度. ...
Multiple Classifier Systems in Remote Sensing: from Basics to Recent Developments
0
2007
Evaluation of Random Forest and Adaboost Tree-based Ensemble Classification and Spectral Band Selection for Ecotope Mapping Using Airborne Hyperspectral Imagery
1
2008
... 集成学习不是特指某种分类算法,而是集成多个基分类器共同决策的机器学习方法[11 ] .该方法通过选择简单的分类算法,获得多个不同的基分类器,然后采用某种集成方式组合成一个强分类器,从而显著提高分类系统的泛化能力和分类精度[12 ] .近年来,随着集成学习理论的提出与发展,基于集成学习的高光谱遥感影像分类算法引起了研究人员的广泛关注.随机森林(Random Forest,RF)是其中最具代表性的集成学习算法[14 ] .该算法基于决策树的集合,利用Bootstrape (自助法)采样方法生成训练子集,基于训练子集训练决策树,每颗决策树投票决策出最终分类结果[15 ] .针对高光谱遥感影像分类面临的高维灾难问题,引入子空间的概念,提出了基于随机子空间的极限学习机集成和基于旋转子空间的极限学习机等两种集成方式[16 ] .Boosting作为一种经典的集成学习方式,通过改变训练样本的权重分布来训练基分类器并将其预测结果组合成一个强分类器.Boosting集成策略中基分类器的选取至关重要,基于AdaBoost的神经网络集成算法利用神经网络算法作为基分类器取得了不错的分类表现[17 ] .由于ELM的高性能,Samat等[18 ] 提出的基于AdaBoost的ELM集成算法分类精度显著优于基于AdaBoost的神经网络集成方法.但基分类器ELM随机化输入权重,导致该集成算法稳定性较差.多特征的利用可以进一步提升分类效果,Chen等[19 ] 提出结合多特征和AdaBoost的算法,在集成过程中将各种类的特征赋予不同的基分类器,但是特征的种类对实验结果影响较大.Xia等[20 ] 将扩展形态学属性剖面作为空间特征,采用随机森林作为基分类器,提出了基于Boosting的随机森林集成,极大地提高了分类精度. ...
Random Forests for Land Cover Classification
1
2006
... 集成学习不是特指某种分类算法,而是集成多个基分类器共同决策的机器学习方法[11 ] .该方法通过选择简单的分类算法,获得多个不同的基分类器,然后采用某种集成方式组合成一个强分类器,从而显著提高分类系统的泛化能力和分类精度[12 ] .近年来,随着集成学习理论的提出与发展,基于集成学习的高光谱遥感影像分类算法引起了研究人员的广泛关注.随机森林(Random Forest,RF)是其中最具代表性的集成学习算法[14 ] .该算法基于决策树的集合,利用Bootstrape (自助法)采样方法生成训练子集,基于训练子集训练决策树,每颗决策树投票决策出最终分类结果[15 ] .针对高光谱遥感影像分类面临的高维灾难问题,引入子空间的概念,提出了基于随机子空间的极限学习机集成和基于旋转子空间的极限学习机等两种集成方式[16 ] .Boosting作为一种经典的集成学习方式,通过改变训练样本的权重分布来训练基分类器并将其预测结果组合成一个强分类器.Boosting集成策略中基分类器的选取至关重要,基于AdaBoost的神经网络集成算法利用神经网络算法作为基分类器取得了不错的分类表现[17 ] .由于ELM的高性能,Samat等[18 ] 提出的基于AdaBoost的ELM集成算法分类精度显著优于基于AdaBoost的神经网络集成方法.但基分类器ELM随机化输入权重,导致该集成算法稳定性较差.多特征的利用可以进一步提升分类效果,Chen等[19 ] 提出结合多特征和AdaBoost的算法,在集成过程中将各种类的特征赋予不同的基分类器,但是特征的种类对实验结果影响较大.Xia等[20 ] 将扩展形态学属性剖面作为空间特征,采用随机森林作为基分类器,提出了基于Boosting的随机森林集成,极大地提高了分类精度. ...
Random Subspace Ensembles for Hyperspectral Image Classification with Extended Morphological Attribute Profiles
1
2015
... 集成学习不是特指某种分类算法,而是集成多个基分类器共同决策的机器学习方法[11 ] .该方法通过选择简单的分类算法,获得多个不同的基分类器,然后采用某种集成方式组合成一个强分类器,从而显著提高分类系统的泛化能力和分类精度[12 ] .近年来,随着集成学习理论的提出与发展,基于集成学习的高光谱遥感影像分类算法引起了研究人员的广泛关注.随机森林(Random Forest,RF)是其中最具代表性的集成学习算法[14 ] .该算法基于决策树的集合,利用Bootstrape (自助法)采样方法生成训练子集,基于训练子集训练决策树,每颗决策树投票决策出最终分类结果[15 ] .针对高光谱遥感影像分类面临的高维灾难问题,引入子空间的概念,提出了基于随机子空间的极限学习机集成和基于旋转子空间的极限学习机等两种集成方式[16 ] .Boosting作为一种经典的集成学习方式,通过改变训练样本的权重分布来训练基分类器并将其预测结果组合成一个强分类器.Boosting集成策略中基分类器的选取至关重要,基于AdaBoost的神经网络集成算法利用神经网络算法作为基分类器取得了不错的分类表现[17 ] .由于ELM的高性能,Samat等[18 ] 提出的基于AdaBoost的ELM集成算法分类精度显著优于基于AdaBoost的神经网络集成方法.但基分类器ELM随机化输入权重,导致该集成算法稳定性较差.多特征的利用可以进一步提升分类效果,Chen等[19 ] 提出结合多特征和AdaBoost的算法,在集成过程中将各种类的特征赋予不同的基分类器,但是特征的种类对实验结果影响较大.Xia等[20 ] 将扩展形态学属性剖面作为空间特征,采用随机森林作为基分类器,提出了基于Boosting的随机森林集成,极大地提高了分类精度. ...
Neural Network based Adaboosting Approach for Hyperspectral Data Classification
1
2012
... 集成学习不是特指某种分类算法,而是集成多个基分类器共同决策的机器学习方法[11 ] .该方法通过选择简单的分类算法,获得多个不同的基分类器,然后采用某种集成方式组合成一个强分类器,从而显著提高分类系统的泛化能力和分类精度[12 ] .近年来,随着集成学习理论的提出与发展,基于集成学习的高光谱遥感影像分类算法引起了研究人员的广泛关注.随机森林(Random Forest,RF)是其中最具代表性的集成学习算法[14 ] .该算法基于决策树的集合,利用Bootstrape (自助法)采样方法生成训练子集,基于训练子集训练决策树,每颗决策树投票决策出最终分类结果[15 ] .针对高光谱遥感影像分类面临的高维灾难问题,引入子空间的概念,提出了基于随机子空间的极限学习机集成和基于旋转子空间的极限学习机等两种集成方式[16 ] .Boosting作为一种经典的集成学习方式,通过改变训练样本的权重分布来训练基分类器并将其预测结果组合成一个强分类器.Boosting集成策略中基分类器的选取至关重要,基于AdaBoost的神经网络集成算法利用神经网络算法作为基分类器取得了不错的分类表现[17 ] .由于ELM的高性能,Samat等[18 ] 提出的基于AdaBoost的ELM集成算法分类精度显著优于基于AdaBoost的神经网络集成方法.但基分类器ELM随机化输入权重,导致该集成算法稳定性较差.多特征的利用可以进一步提升分类效果,Chen等[19 ] 提出结合多特征和AdaBoost的算法,在集成过程中将各种类的特征赋予不同的基分类器,但是特征的种类对实验结果影响较大.Xia等[20 ] 将扩展形态学属性剖面作为空间特征,采用随机森林作为基分类器,提出了基于Boosting的随机森林集成,极大地提高了分类精度. ...
ELM2 : Ensemble Extreme Learning Machines for Hyperspectral Image Classification
1
2014
... 集成学习不是特指某种分类算法,而是集成多个基分类器共同决策的机器学习方法[11 ] .该方法通过选择简单的分类算法,获得多个不同的基分类器,然后采用某种集成方式组合成一个强分类器,从而显著提高分类系统的泛化能力和分类精度[12 ] .近年来,随着集成学习理论的提出与发展,基于集成学习的高光谱遥感影像分类算法引起了研究人员的广泛关注.随机森林(Random Forest,RF)是其中最具代表性的集成学习算法[14 ] .该算法基于决策树的集合,利用Bootstrape (自助法)采样方法生成训练子集,基于训练子集训练决策树,每颗决策树投票决策出最终分类结果[15 ] .针对高光谱遥感影像分类面临的高维灾难问题,引入子空间的概念,提出了基于随机子空间的极限学习机集成和基于旋转子空间的极限学习机等两种集成方式[16 ] .Boosting作为一种经典的集成学习方式,通过改变训练样本的权重分布来训练基分类器并将其预测结果组合成一个强分类器.Boosting集成策略中基分类器的选取至关重要,基于AdaBoost的神经网络集成算法利用神经网络算法作为基分类器取得了不错的分类表现[17 ] .由于ELM的高性能,Samat等[18 ] 提出的基于AdaBoost的ELM集成算法分类精度显著优于基于AdaBoost的神经网络集成方法.但基分类器ELM随机化输入权重,导致该集成算法稳定性较差.多特征的利用可以进一步提升分类效果,Chen等[19 ] 提出结合多特征和AdaBoost的算法,在集成过程中将各种类的特征赋予不同的基分类器,但是特征的种类对实验结果影响较大.Xia等[20 ] 将扩展形态学属性剖面作为空间特征,采用随机森林作为基分类器,提出了基于Boosting的随机森林集成,极大地提高了分类精度. ...
Joint Adaboost and Multifeature based Ensemble for Hyperspectral Image Classification
1
2014
... 集成学习不是特指某种分类算法,而是集成多个基分类器共同决策的机器学习方法[11 ] .该方法通过选择简单的分类算法,获得多个不同的基分类器,然后采用某种集成方式组合成一个强分类器,从而显著提高分类系统的泛化能力和分类精度[12 ] .近年来,随着集成学习理论的提出与发展,基于集成学习的高光谱遥感影像分类算法引起了研究人员的广泛关注.随机森林(Random Forest,RF)是其中最具代表性的集成学习算法[14 ] .该算法基于决策树的集合,利用Bootstrape (自助法)采样方法生成训练子集,基于训练子集训练决策树,每颗决策树投票决策出最终分类结果[15 ] .针对高光谱遥感影像分类面临的高维灾难问题,引入子空间的概念,提出了基于随机子空间的极限学习机集成和基于旋转子空间的极限学习机等两种集成方式[16 ] .Boosting作为一种经典的集成学习方式,通过改变训练样本的权重分布来训练基分类器并将其预测结果组合成一个强分类器.Boosting集成策略中基分类器的选取至关重要,基于AdaBoost的神经网络集成算法利用神经网络算法作为基分类器取得了不错的分类表现[17 ] .由于ELM的高性能,Samat等[18 ] 提出的基于AdaBoost的ELM集成算法分类精度显著优于基于AdaBoost的神经网络集成方法.但基分类器ELM随机化输入权重,导致该集成算法稳定性较差.多特征的利用可以进一步提升分类效果,Chen等[19 ] 提出结合多特征和AdaBoost的算法,在集成过程中将各种类的特征赋予不同的基分类器,但是特征的种类对实验结果影响较大.Xia等[20 ] 将扩展形态学属性剖面作为空间特征,采用随机森林作为基分类器,提出了基于Boosting的随机森林集成,极大地提高了分类精度. ...
Random Forest Ensembles and Extended Multiextinction Profiles for Hyperspectral Image Classification
1
2018
... 集成学习不是特指某种分类算法,而是集成多个基分类器共同决策的机器学习方法[11 ] .该方法通过选择简单的分类算法,获得多个不同的基分类器,然后采用某种集成方式组合成一个强分类器,从而显著提高分类系统的泛化能力和分类精度[12 ] .近年来,随着集成学习理论的提出与发展,基于集成学习的高光谱遥感影像分类算法引起了研究人员的广泛关注.随机森林(Random Forest,RF)是其中最具代表性的集成学习算法[14 ] .该算法基于决策树的集合,利用Bootstrape (自助法)采样方法生成训练子集,基于训练子集训练决策树,每颗决策树投票决策出最终分类结果[15 ] .针对高光谱遥感影像分类面临的高维灾难问题,引入子空间的概念,提出了基于随机子空间的极限学习机集成和基于旋转子空间的极限学习机等两种集成方式[16 ] .Boosting作为一种经典的集成学习方式,通过改变训练样本的权重分布来训练基分类器并将其预测结果组合成一个强分类器.Boosting集成策略中基分类器的选取至关重要,基于AdaBoost的神经网络集成算法利用神经网络算法作为基分类器取得了不错的分类表现[17 ] .由于ELM的高性能,Samat等[18 ] 提出的基于AdaBoost的ELM集成算法分类精度显著优于基于AdaBoost的神经网络集成方法.但基分类器ELM随机化输入权重,导致该集成算法稳定性较差.多特征的利用可以进一步提升分类效果,Chen等[19 ] 提出结合多特征和AdaBoost的算法,在集成过程中将各种类的特征赋予不同的基分类器,但是特征的种类对实验结果影响较大.Xia等[20 ] 将扩展形态学属性剖面作为空间特征,采用随机森林作为基分类器,提出了基于Boosting的随机森林集成,极大地提高了分类精度. ...
Tangent Distance-based Collaborative Representation for Hyperspectral Image Classification
1
2016
... 近年来,协同表示(Collaborative Representation, CR)以模型简单、结构稳定在高光谱遥感分类中得到越来越多的关注.协同表示认为测试样本可以由训练样本集中同类的样本子集进行线性表示,分类依据为某类训练样本子集的表示估计值与测试样本的真实值最为接近.协同表示框架中的基于切空间的协同表示算法[21 ] (Tangent Space Collaborative Representation,TCRC)利用了测试样本的简化切空间,分类精度进一步得到提升.在模式识别领域中,将多重协同表示与Boosting思想相结合的算法[22 ] 已经取得了良好的识别性能,该算法采用CR作为基分类器,分类精度提升有限.因此考虑基于Boosting原理引入分类表现较优的TCRC作为基分类器,可进一步提升高光谱遥感影像分类的准确性和可靠性. ...
Classification and Boosting with Multiple Collaborative Representations
1
2014
... 近年来,协同表示(Collaborative Representation, CR)以模型简单、结构稳定在高光谱遥感分类中得到越来越多的关注.协同表示认为测试样本可以由训练样本集中同类的样本子集进行线性表示,分类依据为某类训练样本子集的表示估计值与测试样本的真实值最为接近.协同表示框架中的基于切空间的协同表示算法[21 ] (Tangent Space Collaborative Representation,TCRC)利用了测试样本的简化切空间,分类精度进一步得到提升.在模式识别领域中,将多重协同表示与Boosting思想相结合的算法[22 ] 已经取得了良好的识别性能,该算法采用CR作为基分类器,分类精度提升有限.因此考虑基于Boosting原理引入分类表现较优的TCRC作为基分类器,可进一步提升高光谱遥感影像分类的准确性和可靠性. ...


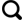





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}