

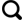


1 引 言
高分辨率光学遥感影像能清晰反映地物的几何结构和纹理特征,可准确获取地块边界和作物种植、倒伏面积等信息,普遍应用于地面样方调查[1]、作物遥感精细分类[2]、农业灾害评估[3]等农情遥感监测业务。在高分辨率遥感影像地物识别与分类过程中,受地物空间异质性大、“同物异谱”等影响,导致其基于最大似然监督分类方法准确性降低、基于面向对象的分类方法存在尺度问题[4]。目前,机器学习是处理高分辨率影像分类提取的主要方法。研究人员采用SVM[5]、随机森林[6]等为代表的浅层机器学习方法进行分类提取,在小范围获得了较高的分类提取精度,但由于模型的网络结构和泛化能力有限,不能处理大量、复杂特征样本,且自动化程度不高[7];通过建立基于深度学习的语义分割模型,如SegNet[8-9]、DeepLabv3+[10-12]、U-net[13-15]等,完成WorldView-2、GF-2、BJ-2等多种高分辨率遥感影像的分类提取任务,实现了农村建筑物、覆盖地膜田块、积雪、甘蔗、水体、设施大棚和果园等地物的信息提取,并取得较传统分类方法和浅层机器学习方法更高的精度。
深度学习通过构建多层隐含神经网络模型,从大量、复杂特征样本数据集中实现特征的自动提取和自动分类,在高分辨率遥感影像分类提取提中表现出显著优势[16-19]。受限于计算机软硬件处理能力,参与训练的样本数据需要切割,尺度过大则会消耗大量计算资源;过小会则会丢失其全局信息,影响分类准确性,因此样本尺度是决定模型训练的效率和最终的分类效果的关键[20-21]。已有研究表明,采用WorldView-2影像提取几何形状规则的农村建筑物,样本尺度为128×128的模型分类精度能够达到最高[8];使用SAR影像和卷积神经网络模型进行海冰分类,训练样本尺度为16×16时模型分类性能最佳[22];针对作物分类提取的最佳尺度选取研究未见相关报道。为建立基于高分辨率遥感影像的小麦分类模型并准确提取空间信息,实现作物种植精细调查,研究以WorldView-2影像为数据源、采用DeepLabv3+和U-net语义分割模型,通过设置不同尺度的样本进行模型优化训练、建立小麦分类模型、提取小麦种植信息;综合对比分析不同尺度样本下模型的精度、效率等指标,以期为基于高分辨率遥感影像的深度学习方法农情信息提取高效应用提供参考。
2 研究区和数据
2.1 研究区概况
研究区位于成都市西南部,涉及邛崃市、大邑县、新津区等部分地区,影像覆盖区域为6 km×19 km,见图1。该区域属亚热带湿润气候,四季分明,平均气温17.8 ℃,年均降雨量约1 300 mm;区域内地势平坦,土壤肥沃,灌溉条件良好,适合多种作物生长,主要作物有小麦、油菜、蔬菜、猕猴桃、葡萄、柑橘等,其余地物包括设施大棚、坑塘、河流、道路和建筑物等。
图1
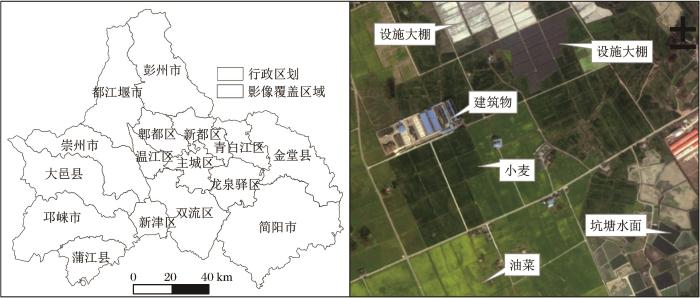
图1
影像覆盖区域及主要解译标志
Fig.1
The area of remote sensing image coverage and interpretation signs of typical features
2.2 数据来源
研究使用的数据包括高分辨率遥感影像数据和地面调查数据。其中,影像数据为通过订购方式获取的2018年2月28日过境的Worldview-2卫星影像,该数据包括全色和多光谱影像,具体光谱信息见表1。地面调查数据于2018年1月中旬在研究区获取包括地物解译标志、调查样方内土地利用现状等数据,为影像地物标注和分类精度验证提供数据支持。
表1 WorldView-2数据光谱信息
Table 1
| 波段名 | 空间分辨率/m | 半值波宽/nm | 中心波长/nm |
|---|---|---|---|
| 全色 | 0.5 | 336.9 | 632.2 |
| 海岸蓝 | 2.0 | 51.8 | 427.3 |
| 蓝色 | 2.0 | 60.8 | 477.9 |
| 绿色 | 2.0 | 69.8 | 546.2 |
| 黄色 | 2.0 | 38.5 | 607.8 |
| 红色 | 2.0 | 59.3 | 658.8 |
| 红边 | 2.0 | 39.8 | 723.7 |
| 近红外1 | 2.0 | 117.8 | 832.5 |
| 近红外2 | 2.0 | 92.5 | 908.0 |
3 研究方法
3.1 训练样本制作
首先在ENVI 5.3中使用格网间距为30 m的DEM数据分别对Worldview-2全色和多光谱影像进行更高精度的正射校正;然后进行数据融合,生成分辨率为0.5 m的8波段多光谱影像数据。结合地面调查采集的解译标志点,对比多种波段组合效果,选取近红外2(R)、红边(G)和红光(B)波段进行假彩色合成突出小麦显示效果,人工目视解译勾绘出小麦种植区域地块边界线,生成标签数据。为提高模型训练速度,提取近红外2、红边和红光3个波段数据用于影像样本数据生产。样本尺度采用常用的128×128、256×256和512×512等3种尺度,分别用64 m×64 m、128 m×128 m和256 m×256 m的规则网格对影像数据和标签数据进行裁减,生成对应的3组样本训练数据集,即7 680个样本尺度大小为128×128、1 920个样本尺度大小为256×256和480个样本尺度为512×512的影像—标签对。将每组样本数据按照60%、20%和20%的比例划分为训练、验证和测试数据,参与模型训练、精度评价和模型测试。
3.2 语义分割模型
DeepLabv3+[25]模型是DeepLab系列最新的网络结构,在特征提取时通过采用空洞卷积控制感受野,集成空间金字塔池化(ASPP)模块提取多尺度特征信息;在DeepLabv3基础上添加解码模块细化对象分割结果;使用Xception模型作为骨干网络来处理分割任务,并在ASPP模块和解码器模块上应用深度可分离卷积,以提高模型精度和速度;DeepLabv3+在处理细节丰富的图像方面较强优势[19]。
3.3 模型训练
模型训练环境为Ubuntu 18.04,采用GPU为NVIDIA Quadro RTX 4000,内存8 G,CUDA版本为11.0;使用基于开源深度学习框架百度PaddlePaddle平台下的图像分割套件PaddleSeg,搭建U-net和DeepLabv3+小麦种植信息提取模型;分别加入3组样本数据集进行U-net和DeepLabv3+模型训练和保存。在训练过程中,主要参数设置包括:网络优化函数为adam,学习率下降方法为poly,DeepLabv3+的模型骨架网络选取Xception_65,初始学习率为0.001,迭代次数为300,训练批数随尺度的升高分别为50、12和4,数据增强方式为按固定尺度(512×512)进行图像缩放,训练的损失函数为Softmax。
3.4 模型评估和预测
根据建立的U-net、DeepLabv3+模型,通过不同尺度的验证数据进行精度评估,综合对比分析不同尺度样本下各模型的总精度、Kappa系数、交并比(IOU)、耗时等指标,为小麦种植信息提取模型建立选择最优的样本尺度;对最佳样本尺度的测试数据进行预测,随机选取12个测试图片的预测分割结果,结合人工标注计算小麦分类的混淆矩阵(包括错分误差、漏分误差、总精度、Kappa系数),并以极大似然监督分类和随机森林分类结果为参照,综合评估建立的深度学习语义分割模型的分类效果。
4 结果与分析
4.1 不同尺度样本训练的模型精度
统计U-net和DeepLabv3+模型在不同尺度的验证数据下模型精度评估结果,其总体精度、Kappa系数、IOU及耗时等指标见表2。根据表2,U-net和DeepLabv3+模型精度评估差别不大,模型总体精度均在94%以上,Kappa系数和IOU分别均在0.82和0.84以上,分类结果较好,模型精度稳定,表明语义分割模型用于高分辨率遥感影像的小麦种植信息提取具有较好的分类效果。对比U-net和DeepLabv3+模型的总体精度、Kappa系数和IOU等指标,U-net模型的整体精度略高于DeepLabv3+,主要表现在U-net的总体精度、Kappa系数和IOU的取值范围分别在94%~96%、0.83~0.87和0.85~0.88之间,而DeepLabv3+则为94%~95%、0.81~0.83和0.83~0.85之间;U-net模型训练耗时整体少于DeepLabv3+。由此表明,较DeepLabv3+模型,U-net模型在基于Worldveiw-2影像的深度学习小麦分类提取中计算速度快、适应性强。
表2 U-net和DeepLabv3+模型在不同尺度样本下的评价指标对比
Table 2
| 模型 | 样本 尺度 | 总精度/% | Kappa | IOU | 耗时 /min |
|---|---|---|---|---|---|
| U-net | 128×128 | 96.30 | 0.871 5 | 0.882 2 | 148 |
| 256×256 | 95.47 | 0.852 9 | 0.866 7 | 129 | |
| 512×512 | 94.68 | 0.835 2 | 0.851 4 | 144 | |
| DeepLabv3+ | 128×128 | 95.15 | 0.833 1 | 0.850 5 | 169 |
| 256×256 | 94.65 | 0.817 9 | 0.838 4 | 163 | |
| 512×512 | 94.62 | 0.831 5 | 0.848 4 | 162 |
从不同尺度样本训练的模型精度来看,U-net和DeepLabv3+模型的精度评价指标整体变化均不大,表明样本尺度对基于语义分割的小麦分类模型训练结果影响较小。不同模型之间对样本尺度变化的灵敏度略有差异,主要表现为:随着样本尺度增加,U-net模型训练后的精度指标变化特征明显,略有降低的趋势,耗时变化较小;而DeepLabv3+的精度评价指标没有明显变化特征,3组样本参与模型训练的耗时相当。综合精度评价指标及模型训练耗时,选取U-net语义分割模型、裁减尺度为256×256的样本建立基于Worldview-2影像的小麦分类模型并准确提取空间信息具有更高的精度和效率。
4.2 基于深度学习分类方法的小麦空间信息提取
根据样本尺度为256×256训练的U-net和DeepLabv3+模型预测结果,计算混淆矩阵,对比极大似然和随机森林分类,统计结果见表3。
表3 不同分类方法小麦提取精度
Table 3
| 分类方法 | 错分误差 | 漏分误差 | 总精度/% | Kappa |
|---|---|---|---|---|
| U-net | 5.30 | 3.12 | 95.63 | 0.912 4 |
| DeepLabv3+ | 5.69 | 4.35 | 94.81 | 0.896 2 |
| 随机森林 | 9.56 | 4.36 | 92.59 | 0.851 5 |
| 极大似然 | 10.88 | 4.75 | 91.61 | 0.831 9 |
基于深度学习语义分割模型的Worldview-2影像小麦种植信息提取精度最高,表现出较好的分类结果,由此说明建立的小麦种植信息提取模型适应性良好。从总精度和Kappa系数来看,U-net和DeepLabv3+模型分别在94%和0.89以上,明显高于基于传统的极大似然和基于浅层机器学习的随机森林,尤其是Kappa系数,差异最为明显。对比错分、漏分误差等指标,U-net和DeepLabv3+模型整体最低,主要表现为两者的错分误差明显低于极大似然和随机森林,也是改善分类效果、提升分类精度的主要原因,进一步说明深度学习语义分割模型在高分辨率遥感影像作物种植信息提取中较传统方法有较大优势。对比深度学习语义分割模型分类结果,U-net模型的错分、漏分误差略低于DeepLabv3+,在处理Worldview-2影像的小麦提取中性能略优于DeepLabv3+。
分别选取U-net和DeepLabv3+模型小麦提取结果的典型区域进行局部放大显示,以极大似然和随机森林分类结果为参照,见图2。基于深度学习语义分割模型的小麦提取效果明显优于随机森林和极大似然,主要表现在:较传统分类方法,语义分割模型的小麦提取结果中几乎不存在部分像元接近小麦的地块边界线、林地等地物;图斑噪声现象明显减少,图斑完整性增强,整体效果得到改善;分类结果无需过多的分类后处理过程,影像处理的自动化程度有较大提升。对比U-net和DeepLabv3+模型的小麦提取效果,二者之间差异不明显,各有优缺点。二者均存在少量漏分现象,如区域一和区域二的红色矩形框内,部分长势较差的小麦均未被DeepLabv3+和U-net提取;均存在不同程度的错分情况,如区域三红色矩形框区域内部分其他作物被错分为小麦,但DeepLabv3+较U-net错分更为明显;在局部区域细节把握方面,DeepLabv3+略显优势,如图2区域四的红色矩形框内,该区域的田坎分割效果较U-net更为清晰。
图2

图2
研究区4个典型区域小麦提取结果对比
Fig.2
Four typical images subsets with their classification results under different methods
5 讨 论
深度学习语义分割模型在处理复杂场景高分辨率影像分类方面较传统分类方法具有绝对优势。研究采用U-net和DeepLabv3+语义分割模型及不同尺度的样本数据,综合模型的训练精度和效率,建立了基于WorldView-2影像的小麦分类提取模型,为高分辨率遥感影像的深度学习种植信息提取提供参考。在分析样本尺度对模型精度的影响时,研究仅采用3种常用尺度的样本数据,得出初步的定性分析结果,进一步定量分析样本尺度对不同模型、不同影像的精度影响,可生产不同尺度、步长的样本数据集,并对影像数据各波段反射率加入指定范围的噪声进行样本扩增,以提高模型的泛化能力,得出最佳尺度选择。
随着高分辨率遥感影像的不断丰富及现代农业种植的信息需求增加,未来需加强地面调查,获取典型地物及作物解译标志等,建立本地化的作物样本数据集,以解决深度学习作物分类提取样本受限的问题,促进深度学习在作物遥感监测中的应用研究。同时,利用高空间分辨率遥感影像丰富的几何结构、纹理特征,采用擅长特征学习的深度学习方法进行农田地块提取;然后以地块为基本单元,应用多源高分辨率遥感数据,进一步实现主要农作物面向地块尺度的精细分类提取[28-30],以期为作物种植信息精准普查、农业生产精细化管理以及区域种植业结构优化等提供信息服务。
6 结 论
本文采用开源深度学习语义分割模型U-net和DeepLabv3+,分别加入尺度为128×128、256×256、512×512的Worldview-2影像样本训练数据集进行模型训练和预测,并以传统的极大似然和浅层机器学习随机森林为参照,得出如下结论:①不同尺度样本下模型训练的精度评价为分类总体精度和Kappa系数在94%~96%之间和0.82~0.87之间,精度评估差别不大,表明作物分类模型精度稳定,样本尺度大小对语义分割模型影响较小。②使用语义分割模型进行WorldView-2影像小麦种植信息提取时,综合模型精度评价指标及耗时,模型为U-net、样本尺度为256×256为最优组合。③深度学习方法的分类体总精度和Kappa系数均在94%和0.89以上,明显优于极大似然和随机森林,该研究建立的小麦遥感分类模型优于传统分类方法。
参考文献
Crop area ground sample survey using Google Earth image-aided
[J].
Fine crop classification by remote sensing in complex planting areas based on field parcel
[J].
地块尺度的复杂种植区作物遥感精细分类
[J].
Estimation of maize lodging area based on Worldview-2 image
[J].
Current issues in high-resolution earth observation technology
[J].
Remote sensing extraction of winter wheat planting area based on SVM
[J].
基于SVM的县域冬小麦种植面积遥感提取
[J].
Application of fandom forest method in maize-soybean accurate identification
[J].
随机森林方法在玉米-大豆精细识别中的应用
[J].
Remote sensed big data era and intelligent information extraction
[J].
遥感大数据时代与智能信息提取
[J].
Rural construction land extraction from high spatial resolution remote sensing image based on SegNet semantic segmentation model
[J].
基于SegNet语义模型的高分辨率遥感影像农村建设用地提取
[J].
Mapping plastic mulched farmland for high resolution images of unmanned aerial vehicle using deep semantic segmentation
[J].
Extraction of snow cover from high-resolution remote sensing imagery using deep learning on a small dataset
[J].
Aquaculture water body information extraction in the Chengdu plain based on Deeplabv3+ model
[J].
基于Deeplabv3+模型的成都平原水产养殖水体信息提取
[J].
Semantic segmentation of citrus-orchard using deep neural networks and multispectral UAV-based imagery
[J].
Extraction of sugarcane from Google Earth image based on the U-Net model
[J].
基于U-Net的甘蔗提取方法
[J].
Water body extraction of high resolution remote sensing image based on improved U-Net Network
[J].
基于改进U-Net网络的高分遥感影像水体提取
[J].
Research on the sparse plastic shed extraction from high resolution images using Envinet 5 Deep Learning Method
[J].
基于Envinet 5的高分辨率遥感影像稀疏塑料大棚提取研究
[J].
Water body extraction from high-resolution satellite remote sensing images based on deep learning
[J].
基于深度学习的高分遥感影像水体提取模型研究
[J].
High spatial fesolution remote sensing image classification based on deep learning
[J].
基于深度学习的高分辨率遥感影像分类研究
[J].
U-Net Neural networks and its application in high resolution satellite image classification
[J].
深度学习U-Net方法及其在高分辨卫星影像分类中的应用
[J].
Convolutional neural network-based remote sensing images segmentation method for extracting winter wheat spatial distribution
[J].
Random forest and rotation forest for fully polarized sar image classification using polarimetric and spatial features
[J].
Multi-scale semantic segmentation of remote sensing image based on deep residential network
[D].
基于深度残差网络的多尺度遥感影像语义分割研究
[D].
Performance of convolutional neural network and deep belief network in sea ice-water classification using SAR imagery
[J].
卷积神经网络和深度置信网络在SAR影像冰水分类的性能评估
[J].
U-Net:convolutional networks for fiomedical image segmentation
[C]∥
U-Net based semantic segmentation method for high resolution remote sensing image
[J].
基于U-Net的高分辨率遥感图像语义分割方法
[J].
Encoder-Decoder with atrous separable convolution for semantic image segmentation
[C]∥
Parcel-based crop distribution extraction using the spatiotemporal collaboration of remote sensing data
[J].
Crop classification method of UVA multispectral remote sensing based on deep semantic segmentation
[J].
基于深度语义分割的无人机多光谱遥感作物分类方法
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}