Semi-automatic classification of tree species in different forest ecosystems by spectral and geometric variables derived from Airborne Digital Sensor (ADS40) and RC30 data
1
2011
... 优势树种分布信息是生物量评估、蓄积量评估、碳储量估算、栖息地质量评估的基础[1-3],也是森林管理部门有效管理和养护森林生态系统的关键[4].在传统森林资源调查中,优势树种分布信息通过实地调查获得,但受地形和天气等因素影响,调查成本高.通过机器学习技术从遥感影像中获取树种空间分布信息成为一种高效便捷的方法[2]. ...
Synergistic use of QuickBird multispectral imagery and LiDAR data for object-based forest species classification
1
2010
... 优势树种分布信息是生物量评估、蓄积量评估、碳储量估算、栖息地质量评估的基础[1-3],也是森林管理部门有效管理和养护森林生态系统的关键[4].在传统森林资源调查中,优势树种分布信息通过实地调查获得,但受地形和天气等因素影响,调查成本高.通过机器学习技术从遥感影像中获取树种空间分布信息成为一种高效便捷的方法[2]. ...
Use of Sentinel-2 for forest classification in mediterranean environments
1
2018
... 优势树种分布信息是生物量评估、蓄积量评估、碳储量估算、栖息地质量评估的基础[1-3],也是森林管理部门有效管理和养护森林生态系统的关键[4].在传统森林资源调查中,优势树种分布信息通过实地调查获得,但受地形和天气等因素影响,调查成本高.通过机器学习技术从遥感影像中获取树种空间分布信息成为一种高效便捷的方法[2]. ...
Tree species classification in the Southern Alps based on the fusion of very high geometrical resolution multispectral/hyperspectral images and LiDAR data
1
2012
... 优势树种分布信息是生物量评估、蓄积量评估、碳储量估算、栖息地质量评估的基础[1-3],也是森林管理部门有效管理和养护森林生态系统的关键[4].在传统森林资源调查中,优势树种分布信息通过实地调查获得,但受地形和天气等因素影响,调查成本高.通过机器学习技术从遥感影像中获取树种空间分布信息成为一种高效便捷的方法[2]. ...
Application of stacking hybrid machine learning algorithms in delineating multi-type flooding in Bangladesh
2
2021
... 随着遥感技术的发展,利用遥感影像进行植被分类的研究层出不穷,但是大区域山区树种遥感分类仍然面临诸多困难.具体包括:①多云多雨的气候条件导致难以获取高质量影像数据.②大范围大比例尺制图需要下载、存储和处理大量的数据,本地单机系统处理效率低下.③复杂的生长环境和树种组成造成“异物同谱”和“同物异谱”现象,仅使用光谱特征难以区分树种.④树种垂直地带性分布导致样本的空间分布和数量不均衡.不同树种分布面积相差较大,样本数据数量与分布的不均衡会影响分类的准确性[5-7]. ...
... 近20 a来,集成学习方法被广泛应用于模式识别、图像处理的各个领域.在土地利用解译、医学和灾害预测和建模等多个方向的研究表明,集成学习可以更好地处理噪声数据以及不平衡数据,从而得到比基分类器更加精确的结果.Jafarzadeh等[8]设计不同的分类场景来比较集成学习算法和基分类器对多光谱、高光谱和PolSAR 3类数据分类的性能,结果表明,对于不同类型的数据,集成学习算法分类性能比基分类器更强大.Rosa Aguilar等[9]使用5个机器学习分类器绘制了马里南部小农耕作系统,基于加权投票策略的集成方法获得了较高分类精度,比最佳的基分类器精度高4.65%.Deepan等[10]采用多层感知机、SVM和RF对PatternNet数据集中的8 000景影像分类,并采用多数投票方法进行集成,发现多数投票方法比单个分类器鲁棒性更高,分类结果更加准确.Kibria等[7]通过集成多层神经网络和KNN算法的初始分类结果,设计了一种决策级融合模型,提高了心管疾病的预测精度.Mahfuzur Rahman等[5]用5种机器学习算法对孟加拉国全国范围内的不同类型洪水易发地区进行评估,结果表明集成方法预测洪水发生概率性能优于5种基础算法.总而言之,集成方法在提高分类准确性和可靠性方面展现出巨大的潜力[11]. ...
Hybrid classifier ensemble for imbalanced data
1
2019
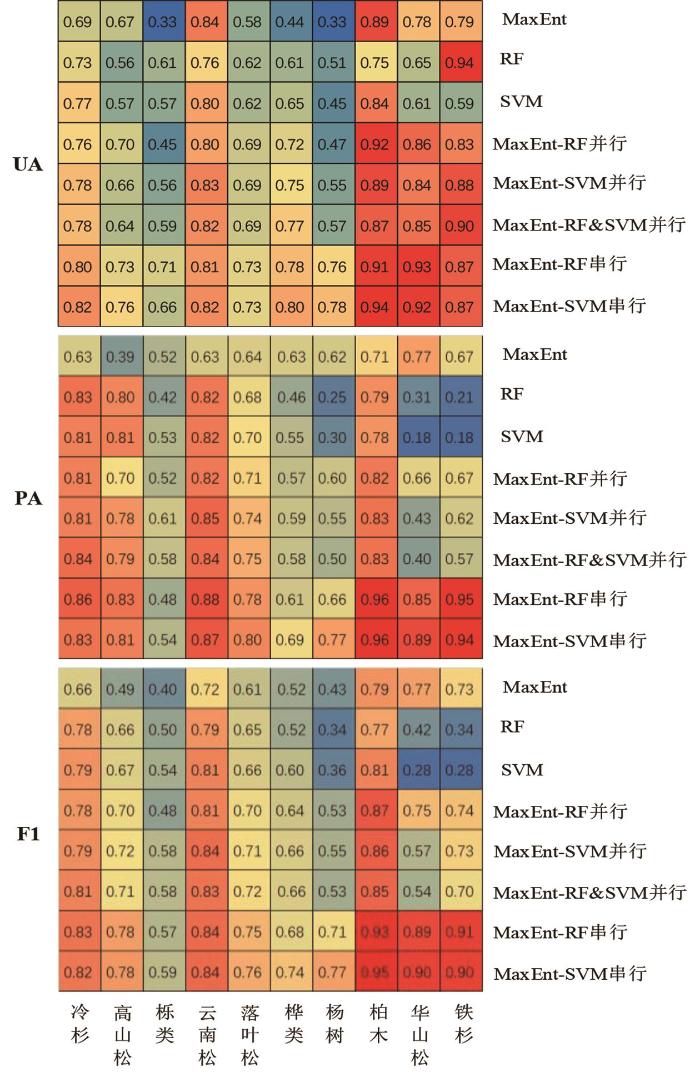
... 值得一提的是,决策融合方法显著改善了小样本类别的分类精度.图8显示每个类别的UA、PA和F1,可以看出每一个类别最佳的UA、PA和F1都是由决策融合方法提供的.特别对于小样本类别如杨树、华山松、柏木和铁杉四类,决策融合方法得到的精度明显高于组件学习器.大量研究也表明集成方法可以缓解数据集中类不平衡问题[6,50-51],本文的分类结果也证实这一说法,对于大样本类别SVM和RF提供了更高的F1,而对于小样本类别MaxEnt提供了比SVM和RF更高的F1,当三者进行决策融合时能同时提高大样本类别和小样本类别的精度. ...
An efficient machine learning-based decision-level fusion model to predict Cardiovascular disease
2
2020
... 随着遥感技术的发展,利用遥感影像进行植被分类的研究层出不穷,但是大区域山区树种遥感分类仍然面临诸多困难.具体包括:①多云多雨的气候条件导致难以获取高质量影像数据.②大范围大比例尺制图需要下载、存储和处理大量的数据,本地单机系统处理效率低下.③复杂的生长环境和树种组成造成“异物同谱”和“同物异谱”现象,仅使用光谱特征难以区分树种.④树种垂直地带性分布导致样本的空间分布和数量不均衡.不同树种分布面积相差较大,样本数据数量与分布的不均衡会影响分类的准确性[5-7]. ...
... 近20 a来,集成学习方法被广泛应用于模式识别、图像处理的各个领域.在土地利用解译、医学和灾害预测和建模等多个方向的研究表明,集成学习可以更好地处理噪声数据以及不平衡数据,从而得到比基分类器更加精确的结果.Jafarzadeh等[8]设计不同的分类场景来比较集成学习算法和基分类器对多光谱、高光谱和PolSAR 3类数据分类的性能,结果表明,对于不同类型的数据,集成学习算法分类性能比基分类器更强大.Rosa Aguilar等[9]使用5个机器学习分类器绘制了马里南部小农耕作系统,基于加权投票策略的集成方法获得了较高分类精度,比最佳的基分类器精度高4.65%.Deepan等[10]采用多层感知机、SVM和RF对PatternNet数据集中的8 000景影像分类,并采用多数投票方法进行集成,发现多数投票方法比单个分类器鲁棒性更高,分类结果更加准确.Kibria等[7]通过集成多层神经网络和KNN算法的初始分类结果,设计了一种决策级融合模型,提高了心管疾病的预测精度.Mahfuzur Rahman等[5]用5种机器学习算法对孟加拉国全国范围内的不同类型洪水易发地区进行评估,结果表明集成方法预测洪水发生概率性能优于5种基础算法.总而言之,集成方法在提高分类准确性和可靠性方面展现出巨大的潜力[11]. ...
Bagging and boosting ensemble classifiers for classification of multispectral, hyperspectral and PolSAR data: A comparative evaluation
1
2021
... 近20 a来,集成学习方法被广泛应用于模式识别、图像处理的各个领域.在土地利用解译、医学和灾害预测和建模等多个方向的研究表明,集成学习可以更好地处理噪声数据以及不平衡数据,从而得到比基分类器更加精确的结果.Jafarzadeh等[8]设计不同的分类场景来比较集成学习算法和基分类器对多光谱、高光谱和PolSAR 3类数据分类的性能,结果表明,对于不同类型的数据,集成学习算法分类性能比基分类器更强大.Rosa Aguilar等[9]使用5个机器学习分类器绘制了马里南部小农耕作系统,基于加权投票策略的集成方法获得了较高分类精度,比最佳的基分类器精度高4.65%.Deepan等[10]采用多层感知机、SVM和RF对PatternNet数据集中的8 000景影像分类,并采用多数投票方法进行集成,发现多数投票方法比单个分类器鲁棒性更高,分类结果更加准确.Kibria等[7]通过集成多层神经网络和KNN算法的初始分类结果,设计了一种决策级融合模型,提高了心管疾病的预测精度.Mahfuzur Rahman等[5]用5种机器学习算法对孟加拉国全国范围内的不同类型洪水易发地区进行评估,结果表明集成方法预测洪水发生概率性能优于5种基础算法.总而言之,集成方法在提高分类准确性和可靠性方面展现出巨大的潜力[11]. ...
A cloud-based multi-temporal ensemble classifier to map smallholder farming systems
1
2018
... 近20 a来,集成学习方法被广泛应用于模式识别、图像处理的各个领域.在土地利用解译、医学和灾害预测和建模等多个方向的研究表明,集成学习可以更好地处理噪声数据以及不平衡数据,从而得到比基分类器更加精确的结果.Jafarzadeh等[8]设计不同的分类场景来比较集成学习算法和基分类器对多光谱、高光谱和PolSAR 3类数据分类的性能,结果表明,对于不同类型的数据,集成学习算法分类性能比基分类器更强大.Rosa Aguilar等[9]使用5个机器学习分类器绘制了马里南部小农耕作系统,基于加权投票策略的集成方法获得了较高分类精度,比最佳的基分类器精度高4.65%.Deepan等[10]采用多层感知机、SVM和RF对PatternNet数据集中的8 000景影像分类,并采用多数投票方法进行集成,发现多数投票方法比单个分类器鲁棒性更高,分类结果更加准确.Kibria等[7]通过集成多层神经网络和KNN算法的初始分类结果,设计了一种决策级融合模型,提高了心管疾病的预测精度.Mahfuzur Rahman等[5]用5种机器学习算法对孟加拉国全国范围内的不同类型洪水易发地区进行评估,结果表明集成方法预测洪水发生概率性能优于5种基础算法.总而言之,集成方法在提高分类准确性和可靠性方面展现出巨大的潜力[11]. ...
Scene classification of remotely sensed images using ensembled machine learning models
2
2021
... 近20 a来,集成学习方法被广泛应用于模式识别、图像处理的各个领域.在土地利用解译、医学和灾害预测和建模等多个方向的研究表明,集成学习可以更好地处理噪声数据以及不平衡数据,从而得到比基分类器更加精确的结果.Jafarzadeh等[8]设计不同的分类场景来比较集成学习算法和基分类器对多光谱、高光谱和PolSAR 3类数据分类的性能,结果表明,对于不同类型的数据,集成学习算法分类性能比基分类器更强大.Rosa Aguilar等[9]使用5个机器学习分类器绘制了马里南部小农耕作系统,基于加权投票策略的集成方法获得了较高分类精度,比最佳的基分类器精度高4.65%.Deepan等[10]采用多层感知机、SVM和RF对PatternNet数据集中的8 000景影像分类,并采用多数投票方法进行集成,发现多数投票方法比单个分类器鲁棒性更高,分类结果更加准确.Kibria等[7]通过集成多层神经网络和KNN算法的初始分类结果,设计了一种决策级融合模型,提高了心管疾病的预测精度.Mahfuzur Rahman等[5]用5种机器学习算法对孟加拉国全国范围内的不同类型洪水易发地区进行评估,结果表明集成方法预测洪水发生概率性能优于5种基础算法.总而言之,集成方法在提高分类准确性和可靠性方面展现出巨大的潜力[11]. ...
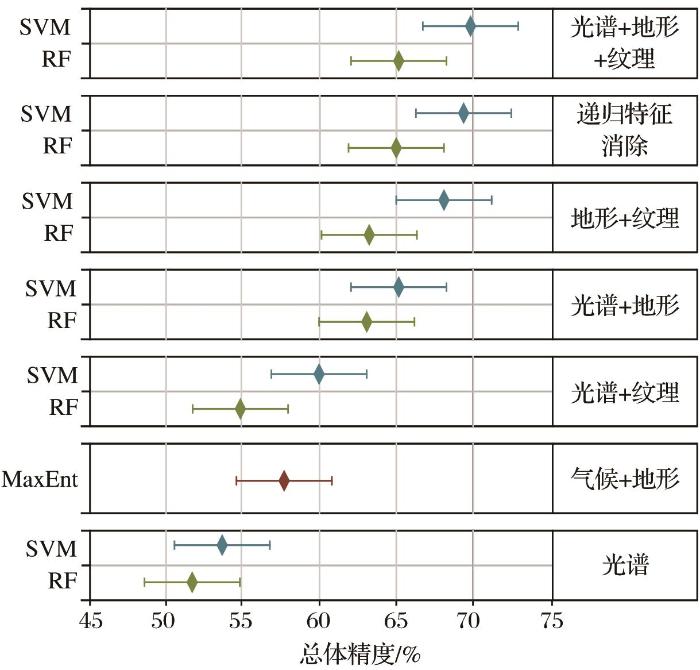
... 决策融合模型中串行集成比并行集成的精度更高,最佳分类精度(OA:80.66%,Kappa:0.78)由MaxEnt-RF串行集成分类器得到,这与现有的在小区域使用高光谱或多光谱图像进行分类的研究相当,甚至高于部分研究的精度[10,15,36,46-49].这一精度表明,在区域尺度上,考虑植被生长的环境信息和遥感数据,通过集成机器学习和生态位模型可以绘制详细的优势树种空间分布图,且方法普适性较高,可以应用于林业清查、环境监测和碳循环估计等应用. ...
Multiple classifier system for remote sensing image classification: A review
2
2012
... 近20 a来,集成学习方法被广泛应用于模式识别、图像处理的各个领域.在土地利用解译、医学和灾害预测和建模等多个方向的研究表明,集成学习可以更好地处理噪声数据以及不平衡数据,从而得到比基分类器更加精确的结果.Jafarzadeh等[8]设计不同的分类场景来比较集成学习算法和基分类器对多光谱、高光谱和PolSAR 3类数据分类的性能,结果表明,对于不同类型的数据,集成学习算法分类性能比基分类器更强大.Rosa Aguilar等[9]使用5个机器学习分类器绘制了马里南部小农耕作系统,基于加权投票策略的集成方法获得了较高分类精度,比最佳的基分类器精度高4.65%.Deepan等[10]采用多层感知机、SVM和RF对PatternNet数据集中的8 000景影像分类,并采用多数投票方法进行集成,发现多数投票方法比单个分类器鲁棒性更高,分类结果更加准确.Kibria等[7]通过集成多层神经网络和KNN算法的初始分类结果,设计了一种决策级融合模型,提高了心管疾病的预测精度.Mahfuzur Rahman等[5]用5种机器学习算法对孟加拉国全国范围内的不同类型洪水易发地区进行评估,结果表明集成方法预测洪水发生概率性能优于5种基础算法.总而言之,集成方法在提高分类准确性和可靠性方面展现出巨大的潜力[11]. ...
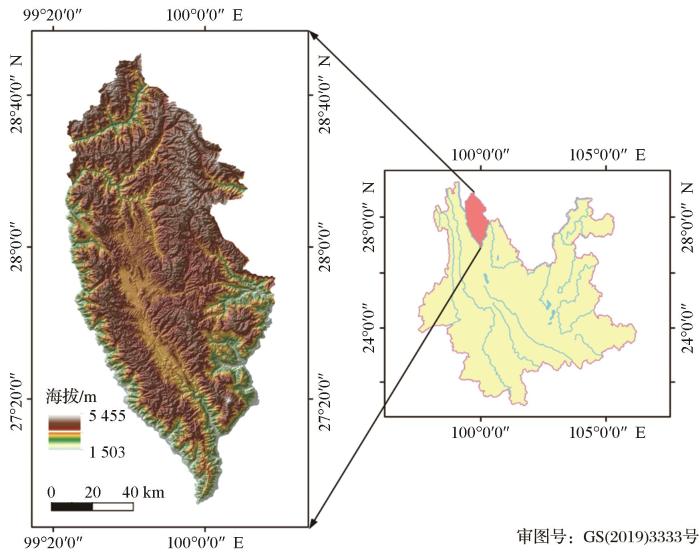
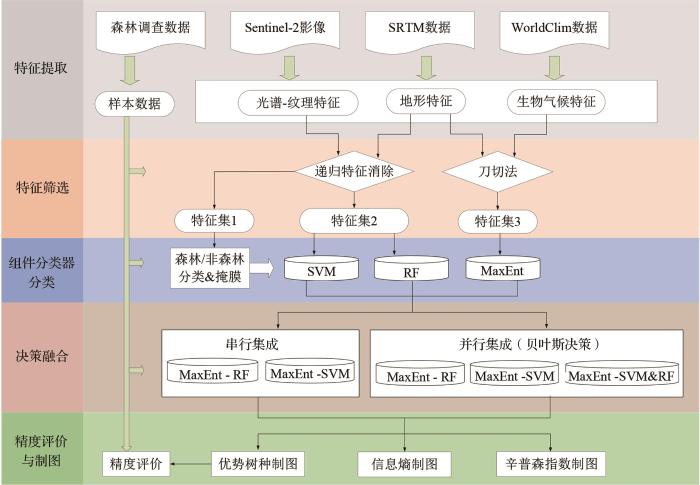
... 集成学习的核心是对多个基分类器初始分类结果实施决策融合来创建集成分类器,以获得更好的分类结果.一个成功的多分类器集成系统在很大程度上取决于组件分类器,高度多样性的组件分类器是构建有效的集成学习系统的关键,组件分类器越精确、差异越大,集成效果越好[11].本文选择SVM、RF和MaxEnt 3种差异较大且在土地利用、土地覆盖变化和森林场景分类中常获得较高精度的3个分类器进行集成. ...
香格里拉县的森林资源及其特点分析
1
2008
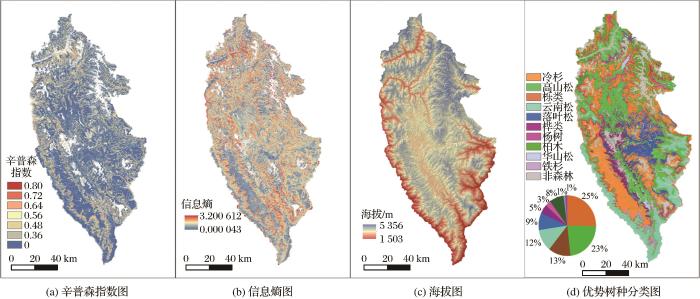
... 香格里拉市隶属云南省迪庆藏族自治州,位于云南省西北部,其地理位置为99°20′~100°19′ E、26°52′~28°52′ N.如图1所示,研究区地势北高南低,最高海拔5 545 m,最低点海拔1 503 m,平均海拔3 459 m,立体气候明显,干湿季分明[12].地形和气候条件的不均匀性导致沿着适宜的环境条件形成各种植被群落.分布较广的优势树种有冷杉、云南松、高山松和栎类等.沿着环境梯度的空间分布模式以及均质斑块使得优势树种的分类制图成为可能. ...
香格里拉县的森林资源及其特点分析
1
2008
... 香格里拉市隶属云南省迪庆藏族自治州,位于云南省西北部,其地理位置为99°20′~100°19′ E、26°52′~28°52′ N.如图1所示,研究区地势北高南低,最高海拔5 545 m,最低点海拔1 503 m,平均海拔3 459 m,立体气候明显,干湿季分明[12].地形和气候条件的不均匀性导致沿着适宜的环境条件形成各种植被群落.分布较广的优势树种有冷杉、云南松、高山松和栎类等.沿着环境梯度的空间分布模式以及均质斑块使得优势树种的分类制图成为可能. ...
Evaluation of different machine learning algorithms for scalable classification of tree types and tree species based on Sentinel-2 data
1
2018
... Sentinel-2有5 d的高时间分辨率,包括从可见光(VIS)和近红外(NIR)波段到短波红外(SWIR)波段的13个波段,可见光的R、G、B和NIR波段的空间分辨率为10 m,4个红边波段空间分辨率为20 m,轨道宽度为290 km,这使得Sentinel-2适合大规模的森林类型和树种分类任务[13-15]. ...
Forest stand species mapping using the Sentinel-2 time series
0
2019
Mapping forest type and Tree Species on a regional scale using multi-temporal Sentinel-2 data
3
2019
... Sentinel-2有5 d的高时间分辨率,包括从可见光(VIS)和近红外(NIR)波段到短波红外(SWIR)波段的13个波段,可见光的R、G、B和NIR波段的空间分辨率为10 m,4个红边波段空间分辨率为20 m,轨道宽度为290 km,这使得Sentinel-2适合大规模的森林类型和树种分类任务[13-15]. ...
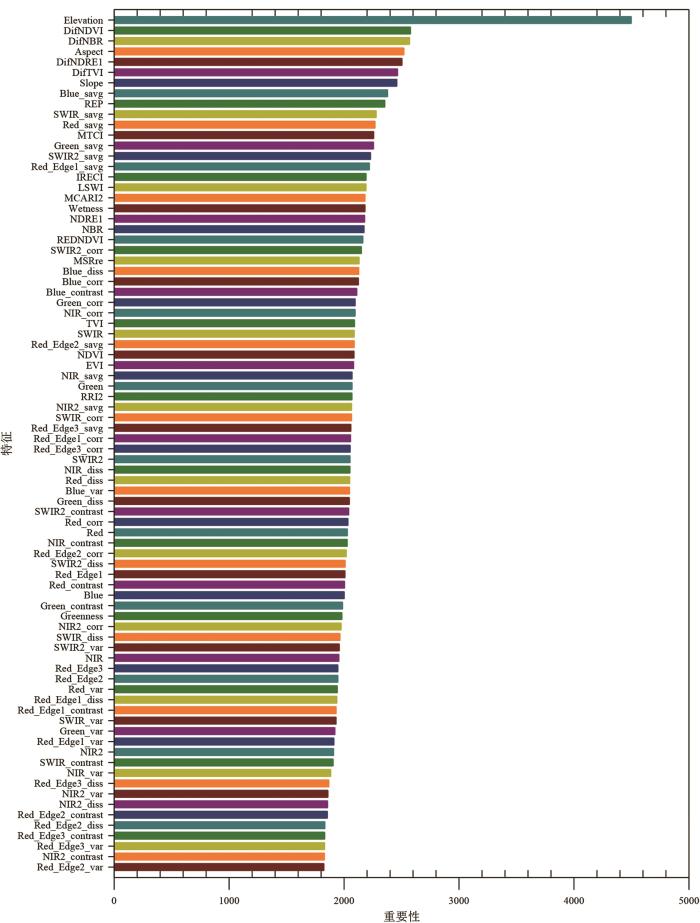
... 对于遥感因子,首先,选择SVM分类器对春、夏、秋、冬4景影像的83个遥感因子分别进行分类,确定最佳的分类季相,表4展示了分类结果.当使用夏季影像时获得的分类精度最高,OA为69.55%,Kappa为0.65;当使用冬季影像时取得的精度最低,OA精度为66.76%,Kappa为0.51.虽然经过去云后夏季影像最少,却是区分树种最佳的季相,这与Salvatore Praticò等的研究结论一致[42].然后,评价夏季83维特征的重要性得分,如图5所示,高程是绘制优势树种空间分布最重要的变量,冷杉、高山松和云南松分布在不同海拔梯度,分类结果表明三者之间混淆程度较低.许多研究表明加入海拔、坡向等辅助数据可以提高植被分类的精度[15,43].当然,其重要程度是根据研究区而定,一些研究的研究区地形平坦,多个树种分布在相同的地形条件,会使得地形特征在模型中解释力变小.光谱特征中,春季和秋季两个季节的差值指数的重要性得分较高,说明在香格里拉地区,各树种生长和衰老模式沿海拔梯度的变化而表现出光谱异质性,这有助于区分各树种.其次是基于红边波段构建的植被指数,如REP、MTCI、IRECI、LSWI、MCARI2等,说明了红边波段在树种制图中的重要性.纹理特征中由各波段计算的SAVG重要性得分值较高. ...
... 决策融合模型中串行集成比并行集成的精度更高,最佳分类精度(OA:80.66%,Kappa:0.78)由MaxEnt-RF串行集成分类器得到,这与现有的在小区域使用高光谱或多光谱图像进行分类的研究相当,甚至高于部分研究的精度[10,15,36,46-49].这一精度表明,在区域尺度上,考虑植被生长的环境信息和遥感数据,通过集成机器学习和生态位模型可以绘制详细的优势树种空间分布图,且方法普适性较高,可以应用于林业清查、环境监测和碳循环估计等应用. ...
Mapping plant functional types in Northwest Himalayan foothills of India using random forest algorithm in Google Earth Engine
1
2020
... 生物气候数据由(http:∥www.wordclim.org)网站上获得.如表1所示,此数据集包含19维空间分辨率为1 km的特征,分别代表年度趋势(年均温度、年降水量)、季节性(年度温差和降水量)以及极端或限制性环境因素(最冷和最热月份的温度,以及湿季和旱季的降水量)[16-17]. ...
Very high resolution interpolated climate surfaces for global land areas
1
2005
... 生物气候数据由(http:∥www.wordclim.org)网站上获得.如表1所示,此数据集包含19维空间分辨率为1 km的特征,分别代表年度趋势(年均温度、年降水量)、季节性(年度温差和降水量)以及极端或限制性环境因素(最冷和最热月份的温度,以及湿季和旱季的降水量)[16-17]. ...
An investigation into robust spectral indices for leaf chlorophyll estimation
1
2011
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
Evaluation of the MERIS terrestrial chlorophyll index (MTCI)
1
2007
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
30 m resolution global annual burned area mapping based on Landsat Images and Google Earth Engine
1
2019
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
Validation of the cotton crop coefficient estimation model based on Sentinel-2 imagery and eddy covariance measurements
1
2019
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
Estimating chlorophyll content from hyperspectral vegetation indices: Modeling and validation
1
2008
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
Land Surface Water Index (LSWI) response to rainfall and NDVI using the MODIS Vegetation Index product
1
2010
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
A review of remote sensing methods for biomass feedstock production
1
2011
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
An evaluation of noninvasive methods to estimate foliar chlorophyll content
1
2002
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
Remote sensing of forest biophysical variables using HyMap imaging spectrometer data
1
2005
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
On the relation between NDVI, fractional vegetation cover, and leaf area index
1
1997
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
Evapotranspiration on western US rivers estimated using the Enhanced Vegetation Index from MODIS and data from eddy covariance and Bowen ratio flux towers
1
2005
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
Comparative analysis of EO-1 ALI and Hyperion, and Landsat ETM+ data for mapping forest crown closure and leaf area index
1
2008
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
Statistical derivation of fPAR and LAI for irrigated cotton and rice in arid Uzbekistan by combining multi-temporal RapidEye data and ground measurements
1
2010
... 将4个子时间序列影像以像素为单位按中值合成得到4景合成影像,基于4景合成影像分别提取29维光谱特征、50维纹理特征,外加3维地形特征.如表3所示,合成的4景影像均有83维特征.光谱特征包括3类,第一类是合成影像的蓝色到短波红外的10个波段(Blue、Green、Red、RedEdge-1、RedEdge-2、RedEdge-3、NIR、RedEdge-4、SWIR-1、SWIR-2);第二类是植被指数,包括三角植被指数(Triangular Vegetation Index, TVI)[18]、陆地叶绿素指数(MERIS Terrestrial Chlorophyll Index, MTCI)[19]、归一化火烧指数(Normalized Burn Ratio, NBR)[20]、反红边叶绿素指数(Inverted Red-Edge Chlorophyll Index, IRECI)[21]、综合叶绿素光谱指数(Modified Chlorophyll Absorption Ratio Index, MCARI)[22]、陆地表面水体指数(Land Surface Water Index, LSWI)[23]、归一化差异红边指数(Normalized Difference Red Edge Index, NDRE)[24]、叶绿素归一化指数(Normalized Difference 750/705 Chl NDI, Chl NDI)[25]、红边位置指数(Red-Edge Position Index, REP)[26]、归一化植被指数(Normalized Difference Vegetation Index, NDVI)[27]、增强型植被指数(Enhanced Vegetation Index,EVI)[28]、修正简单植被指数(Modified Simple Ratio Index,MSR)[29]、红边比值植被指数(RedEdge Ratio Index 2,RRI2)[30],以及基于合成的春秋两季影像构建的TVI、NDRE、NDVI的差值指数(DIFTVI、DIFNDRE、DIFNDVI)等.第三类是缨帽变换的绿度(TCGRE)和湿度(TCWET)分量.基于灰度共生矩阵(GLCM)对蓝色到短波红外10个波段分别计算5种纹理特征,表3显示了提取的纹理特征及其计算公式,其中和是矩阵中行和列数,是均值,是标准差. ...
Comparison of machine learning methods for mapping the stand characteristics of temperate forests using multi-spectral Sentinel-2 data
1
2020
... 对于RF和SVM,由光谱、纹理和地形特征构成的83维遥感因子作为输入,首先对83维遥感因子进行归一化处理,再用递归特征消除(Recursive Feature Elimination, RFE)算法[31]选择最佳的森林与非森林分类以及优势树种分类特征. ...
Comparison of machine-learning methods for urban land-use mapping in Hangzhou City, China
1
2020
... SVM因计算速度快和泛化能力强等特点,被广泛用于植被分类.SVM通过非线性变换将输入的线性不可分空间转换成线性可分的高维特征空间,然后在这个高维特征空间中寻找最优超平面.最优超平面不仅能够正确地对所有训练样本进行分类,而且能最大化最接近分类平面的点之间的距离,即能够以最大化分类间隔以分离不同的类别[32].Shao的研究结果表明,SVM在小的训练数据集上表现出比ANN和CART更好的性能[33].Matthew等用Sentinel-2数据和SVM对加利福尼亚州索诺马县的16种树种分类,分类精度为74.3%[34]. ...
Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points
1
2012
... SVM因计算速度快和泛化能力强等特点,被广泛用于植被分类.SVM通过非线性变换将输入的线性不可分空间转换成线性可分的高维特征空间,然后在这个高维特征空间中寻找最优超平面.最优超平面不仅能够正确地对所有训练样本进行分类,而且能最大化最接近分类平面的点之间的距离,即能够以最大化分类间隔以分离不同的类别[32].Shao的研究结果表明,SVM在小的训练数据集上表现出比ANN和CART更好的性能[33].Matthew等用Sentinel-2数据和SVM对加利福尼亚州索诺马县的16种树种分类,分类精度为74.3%[34]. ...
Comparison of multi-seasonal Landsat 8, Sentinel-2 and hyperspectral images for mapping forest alliances in Northern California
1
2020
... SVM因计算速度快和泛化能力强等特点,被广泛用于植被分类.SVM通过非线性变换将输入的线性不可分空间转换成线性可分的高维特征空间,然后在这个高维特征空间中寻找最优超平面.最优超平面不仅能够正确地对所有训练样本进行分类,而且能最大化最接近分类平面的点之间的距离,即能够以最大化分类间隔以分离不同的类别[32].Shao的研究结果表明,SVM在小的训练数据集上表现出比ANN和CART更好的性能[33].Matthew等用Sentinel-2数据和SVM对加利福尼亚州索诺马县的16种树种分类,分类精度为74.3%[34]. ...
A framework for large-area mapping of past and present cropping activity using seasonal Landsat images and time series metrics
1
2016
... RF是一种bagging类型的集成算法,它利用多个决策树来合成预测.RF分类器通常比单个决策树具有更高的分类精度,当输入高维特征时,RF算法表现出较好的性能.Michael Schmidt通过陆地卫星图像对作物/非作物分类时,比较了几种机器学习算法,结果证明,RF算法提供了更好的准确性[35].Agata Ho´ sciło等使用Sentinel-2数据和RF算法对朝鲜高城郡的5种主要树种分类,精度达到80%[36]. ...
Machine learning for tree species classification using Sentinel-2 spectral information, crown texture, and environmental variables
2
2020
... RF是一种bagging类型的集成算法,它利用多个决策树来合成预测.RF分类器通常比单个决策树具有更高的分类精度,当输入高维特征时,RF算法表现出较好的性能.Michael Schmidt通过陆地卫星图像对作物/非作物分类时,比较了几种机器学习算法,结果证明,RF算法提供了更好的准确性[35].Agata Ho´ sciło等使用Sentinel-2数据和RF算法对朝鲜高城郡的5种主要树种分类,精度达到80%[36]. ...
... 决策融合模型中串行集成比并行集成的精度更高,最佳分类精度(OA:80.66%,Kappa:0.78)由MaxEnt-RF串行集成分类器得到,这与现有的在小区域使用高光谱或多光谱图像进行分类的研究相当,甚至高于部分研究的精度[10,15,36,46-49].这一精度表明,在区域尺度上,考虑植被生长的环境信息和遥感数据,通过集成机器学习和生态位模型可以绘制详细的优势树种空间分布图,且方法普适性较高,可以应用于林业清查、环境监测和碳循环估计等应用. ...
Research advances in modelling plant species distribution in China
1
2019
... MaxEnt是另一类被广泛用于确定树种空间分布的方法[37].它假设不完整的经验概率分布可以近似于一些环境因子约束的最大熵的概率分布,并且该分布近似于物种潜在地理分布[38].即使样本的尺寸和空间间隔小,MaxEnt也能得到稳定可靠的预测精度.多项研究表明MaxEnt模型的预测结果接近真实分布[39-40]. ...
Maximum entropy modeling of species geographic distributions
1
2006
... MaxEnt是另一类被广泛用于确定树种空间分布的方法[37].它假设不完整的经验概率分布可以近似于一些环境因子约束的最大熵的概率分布,并且该分布近似于物种潜在地理分布[38].即使样本的尺寸和空间间隔小,MaxEnt也能得到稳定可靠的预测精度.多项研究表明MaxEnt模型的预测结果接近真实分布[39-40]. ...
Maxent modeling for predicting the potential distribution of endangered medicinal plant (H. riparia Lour) in Yunnan, China
1
2016
... MaxEnt是另一类被广泛用于确定树种空间分布的方法[37].它假设不完整的经验概率分布可以近似于一些环境因子约束的最大熵的概率分布,并且该分布近似于物种潜在地理分布[38].即使样本的尺寸和空间间隔小,MaxEnt也能得到稳定可靠的预测精度.多项研究表明MaxEnt模型的预测结果接近真实分布[39-40]. ...
Under predicted climate change: Distribution and ecological niche modelling of six native tree species in Gilgit-Baltistan, Pakistan
1
2020
... MaxEnt是另一类被广泛用于确定树种空间分布的方法[37].它假设不完整的经验概率分布可以近似于一些环境因子约束的最大熵的概率分布,并且该分布近似于物种潜在地理分布[38].即使样本的尺寸和空间间隔小,MaxEnt也能得到稳定可靠的预测精度.多项研究表明MaxEnt模型的预测结果接近真实分布[39-40]. ...
Measurement of diversity
1
1949
... 辛普森指数(Simpson Diversity Index, SI)[41]的定义如下: ...
Machine learning classification of mediterranean forest habitats in Google Earth Engine based on seasonal Sentinel-2 time-series and input image composition optimisation
1
2021
... 对于遥感因子,首先,选择SVM分类器对春、夏、秋、冬4景影像的83个遥感因子分别进行分类,确定最佳的分类季相,表4展示了分类结果.当使用夏季影像时获得的分类精度最高,OA为69.55%,Kappa为0.65;当使用冬季影像时取得的精度最低,OA精度为66.76%,Kappa为0.51.虽然经过去云后夏季影像最少,却是区分树种最佳的季相,这与Salvatore Praticò等的研究结论一致[42].然后,评价夏季83维特征的重要性得分,如图5所示,高程是绘制优势树种空间分布最重要的变量,冷杉、高山松和云南松分布在不同海拔梯度,分类结果表明三者之间混淆程度较低.许多研究表明加入海拔、坡向等辅助数据可以提高植被分类的精度[15,43].当然,其重要程度是根据研究区而定,一些研究的研究区地形平坦,多个树种分布在相同的地形条件,会使得地形特征在模型中解释力变小.光谱特征中,春季和秋季两个季节的差值指数的重要性得分较高,说明在香格里拉地区,各树种生长和衰老模式沿海拔梯度的变化而表现出光谱异质性,这有助于区分各树种.其次是基于红边波段构建的植被指数,如REP、MTCI、IRECI、LSWI、MCARI2等,说明了红边波段在树种制图中的重要性.纹理特征中由各波段计算的SAVG重要性得分值较高. ...
Evaluation of machine learning algorithms for forest stand species mapping using Sentinel-2 imagery and environmental data in the Polish Carpathians
2
2020
... 对于遥感因子,首先,选择SVM分类器对春、夏、秋、冬4景影像的83个遥感因子分别进行分类,确定最佳的分类季相,表4展示了分类结果.当使用夏季影像时获得的分类精度最高,OA为69.55%,Kappa为0.65;当使用冬季影像时取得的精度最低,OA精度为66.76%,Kappa为0.51.虽然经过去云后夏季影像最少,却是区分树种最佳的季相,这与Salvatore Praticò等的研究结论一致[42].然后,评价夏季83维特征的重要性得分,如图5所示,高程是绘制优势树种空间分布最重要的变量,冷杉、高山松和云南松分布在不同海拔梯度,分类结果表明三者之间混淆程度较低.许多研究表明加入海拔、坡向等辅助数据可以提高植被分类的精度[15,43].当然,其重要程度是根据研究区而定,一些研究的研究区地形平坦,多个树种分布在相同的地形条件,会使得地形特征在模型中解释力变小.光谱特征中,春季和秋季两个季节的差值指数的重要性得分较高,说明在香格里拉地区,各树种生长和衰老模式沿海拔梯度的变化而表现出光谱异质性,这有助于区分各树种.其次是基于红边波段构建的植被指数,如REP、MTCI、IRECI、LSWI、MCARI2等,说明了红边波段在树种制图中的重要性.纹理特征中由各波段计算的SAVG重要性得分值较高. ...
... 从图9(c)中可以看出,辛普森指数图和信息熵图显示分类精度高的区域在海拔较高的同质林分高、森林和冠层覆盖率高和优势树种丰度聚集分布地区,这些区域有较大的原生森林斑块,这些区域的特点是特征相对纯净.这些结论与Ewa Grabska等人一致[43].分类精度差的区域位于海拔过渡区,这些环境限制较低,多个树种的生境存在重叠,树种组成异质程度较高. ...
Evolving hybrid ensembles of learning machines for better generalisation
1
2006
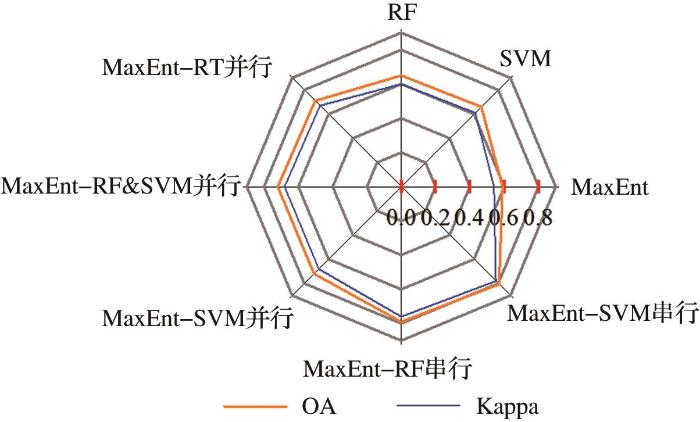
... 研究对比了3个组件学习器与5类决策融合模型的分类精度.图7显示了各种模型的OA和Kappa.从图中可以看出,决策融合模型分类精度均优于组件分类器,证明了串行集成和并行集成两种范式都可以提高分类精度.与之前的研究一致,多样性和准确性是构建集成模型的两个关键[44-45],组件分类器间良好的性能和相互间的差异使得决策融合模型的分类精度较之组件学习器精度提高了5%~21%. ...
Multi-classifier systems: Review and a roadmap for developers
1
2006
... 研究对比了3个组件学习器与5类决策融合模型的分类精度.图7显示了各种模型的OA和Kappa.从图中可以看出,决策融合模型分类精度均优于组件分类器,证明了串行集成和并行集成两种范式都可以提高分类精度.与之前的研究一致,多样性和准确性是构建集成模型的两个关键[44-45],组件分类器间良好的性能和相互间的差异使得决策融合模型的分类精度较之组件学习器精度提高了5%~21%. ...
Forest cover mapping and pinus species classification using very high-resolution satellite images and random forest
1
2021
... 决策融合模型中串行集成比并行集成的精度更高,最佳分类精度(OA:80.66%,Kappa:0.78)由MaxEnt-RF串行集成分类器得到,这与现有的在小区域使用高光谱或多光谱图像进行分类的研究相当,甚至高于部分研究的精度[10,15,36,46-49].这一精度表明,在区域尺度上,考虑植被生长的环境信息和遥感数据,通过集成机器学习和生态位模型可以绘制详细的优势树种空间分布图,且方法普适性较高,可以应用于林业清查、环境监测和碳循环估计等应用. ...
Earth observation and biodiversity big data for forest habitat types classification and mapping
0
2021
Exploring the potential of land surface phenology and seasonal cloud free composites of one year of Sentinel-2 imagery for tree species mapping in a mountainous region
0
2021
Mapping tree species in temperate deciduous woodland using time-series multi-spectral data
1
2010
... 决策融合模型中串行集成比并行集成的精度更高,最佳分类精度(OA:80.66%,Kappa:0.78)由MaxEnt-RF串行集成分类器得到,这与现有的在小区域使用高光谱或多光谱图像进行分类的研究相当,甚至高于部分研究的精度[10,15,36,46-49].这一精度表明,在区域尺度上,考虑植被生长的环境信息和遥感数据,通过集成机器学习和生态位模型可以绘制详细的优势树种空间分布图,且方法普适性较高,可以应用于林业清查、环境监测和碳循环估计等应用. ...
RUESVMs: An ensemble method to handle the class imbalance problem in land cover mapping using Google Earth Engine
1
2020
... 值得一提的是,决策融合方法显著改善了小样本类别的分类精度.图8显示每个类别的UA、PA和F1,可以看出每一个类别最佳的UA、PA和F1都是由决策融合方法提供的.特别对于小样本类别如杨树、华山松、柏木和铁杉四类,决策融合方法得到的精度明显高于组件学习器.大量研究也表明集成方法可以缓解数据集中类不平衡问题[6,50-51],本文的分类结果也证实这一说法,对于大样本类别SVM和RF提供了更高的F1,而对于小样本类别MaxEnt提供了比SVM和RF更高的F1,当三者进行决策融合时能同时提高大样本类别和小样本类别的精度. ...
Ensemble strategy for hard classifying samples in class-imbalanced data set
1
2018
... 值得一提的是,决策融合方法显著改善了小样本类别的分类精度.图8显示每个类别的UA、PA和F1,可以看出每一个类别最佳的UA、PA和F1都是由决策融合方法提供的.特别对于小样本类别如杨树、华山松、柏木和铁杉四类,决策融合方法得到的精度明显高于组件学习器.大量研究也表明集成方法可以缓解数据集中类不平衡问题[6,50-51],本文的分类结果也证实这一说法,对于大样本类别SVM和RF提供了更高的F1,而对于小样本类别MaxEnt提供了比SVM和RF更高的F1,当三者进行决策融合时能同时提高大样本类别和小样本类别的精度. ...
Mapping a specific class with an ensemble of classifiers
1
2007
... 辛普森指数图和信息熵图是对分类不确定性的可视化表达.集成方法产生了类分配不确定性信息,辛普森指数图评估了5种决策融合模型在每个像素上的分类一致性,见图9(a),而信息熵图是基于精度最高的模型计算得到,见图9(b),二者在空间有着很好的一致性.事实上,这二者信息可以体现分类结果的可信度,是对标准精度评估的补充,可用于分类后处理和分析[52]. ...


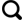



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}