

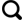


1 引 言
遥感图像已成为获取地表信息的主要数据来源,遥感图像语义分割广泛应用于土地监测、城市规划、环境监测等领域。随着卫星遥感技术的不断发展,遥感图像的分辨率有很大的提高,高分辨率遥感图像中细小目标得到呈现,地物目标的尺寸差异大成为遥感图像语义分割的新挑战。
图像语义分割需要同时完成分类和定位两个任务:将图像中的每个物体精确分割出来,同时对每个物体进行分类。但是,这两个任务是相互矛盾的[1],对于分类任务,要求模型对各种几何变化(例如旋转、平移)具有不变性;对于定位任务,模型应该对几何变化具有敏感性,因为每个像素都需要在正确的位置上进行分类。传统遥感图像语义分割方法多采用无监督或有监督的学习方法,例如K-means[2]、期望最大化(Exceptation Maximization,EM)算法[3]、决策树方法[4]、支持向量机(Support Vector Machine,SVM)算法[5]、最大似然法[6]、随机森林(Random Forests,RF)算法[7]和其他机器学习算法。这些传统的机器学习方法更多地依赖于光谱特征[8],而未充分利用高分辨率遥感影像的空间上下文和纹理信息,分割精度通常较低。
遥感图像中不同类别的地物可能具有相似的光谱特征,因此需要提取空间上下文信息来提升分割效果。随着深度学习方法被逐渐应用到图像分割领域,卷积神经网络(Convolutional Neural Networks,CNN)在光谱和空间上下文信息提取方面具有很强的能力。全卷积网络(Fully Convolution Network,FCN)[9]显著地提高了图像语义分割的精度,但仍存在空间上下文信息利用不足的问题。空间上下文信息在图像语义分割领域发挥着至关重要的作用,引入更多的空间上下文信息有助于更好地区分目标对象[10]。Ronneberger等[11]提出的U-Net模型,使用编码器—解码器对称结构和跳跃连接来提取空间上下文信息,近几年在遥感图像语义分割领域逐渐被采用。Badrinarayanan等[12]提出的SegNet网络也是采用编码器—解码器结构来提取空间上下文信息,其不同点是在下采样时记住最大池化的索引位置,在上采样时调用该索引位置,对特征图进行不断补全,从而完成上采样操作。Chen等[13-16]提出的DeepLab系列网络模型在图像语义分割上具有很大的影响力,为了获取更丰富的空间上下文信息,DeepLab V2分割网络首次提出了空洞空间金字塔池化模块(Atrous Spatial Pyramid Pooling,ASPP),利用ASPP扩大感受野来增强空间上下文信息的提取。之后的DeepLab V3在ASPP模块中引入了全局平均池化(Global Average Pooling,GAP),更好地利用了全局信息。DeepLab V3+模型进一步增加了编码器结构,将编码器输出的低层特征和ASPP输出的高层特征相融合,以获得多尺度的特征信息,提高了分割效果。
经典的语义分割网络模型通常难以捕捉遥感图像的地物轮廓信息,难以提取地物之间的空间上下文关系,从而导致分割边界比较粗糙、细小目标容易被漏分、大目标难以完整地被分割出来。LANet[20]网络模型针对遥感图像语义信息丰富的特性设计了基于补丁级别的注意力机制提取空间上下文信息,在遥感图像语义分割上取得了良好的分割效果。Hou等[21]将位置信息嵌入到了通道注意力中提出了一种新的注意力机制,即Coordinate Attention,该注意力机制在自然图像上取得了较好的分割效果,但在遥感数据集上的效果不是很理想。Peng等[1]提出一种全局卷积网络模型,在整个网络模型中堆叠多个GCM来扩大感受野,获取更丰富的空间上下文信息。二维漏斗激活函数(Funnel ReLU,FReLU)以像素本身或其空间上下文信息作为非线性函数条件产生空间依赖关系,能形成不同大小的激活区域块,有利于捕获细小目标,细化物体分割边界[22]。
引入注意力机制,获取全局特征和产生空间依赖关系可以更好地提取遥感图像上下文信息、细化分割边界。受到这些工作的启发,对LANet网络模型进行改进,提出了遥感图像语义分割的全局卷积模块与局部注意力网络模型(GCM+-LANet),并在遥感数据集上与经典的语义分割网络进行了对比实验。实验的贡献主要包括以下4个方面:
(1)采用LANet网络模型作为基础网络进行语义分割,提取丰富的上下文信息。
(2)受全卷积网络模型的启发,在GCM模块上进行改进,提出了GCM+模块并加入到LANet网络模型中,提取全局特征,提高大尺寸地物目标的分割精度。
(3)引用FReLU激活函数提升细长或较小目标物体分割效果,细化分割边界。
(4)聚合使用GCM+模块和FReLU激活函数,减少高分辨率遥感图像地物尺寸差异大对分割结果的影响。
2 研究方法
2.1 LANet网络模型
2.1.1 PAM
图1
2.1.2 AEM
由于低层特征在空间分布上与高层特征不同,因此很难有效利用低层特征。利用低层特征最常用的方法是将它们与高层特征连接,但这样处理对最终效果只会有轻微的提升。AEM(如图2所示)为了充分利用低层特征,将局部注意力从高层特征嵌入到低层特征中,使得低层特征在保留其原有空间信息的同时进一步引入上下文信息,突破其感受野的限制,也缩小了低层特征和高层特征之间的差距。
图2

2.2 GCM+-LANet网络模型
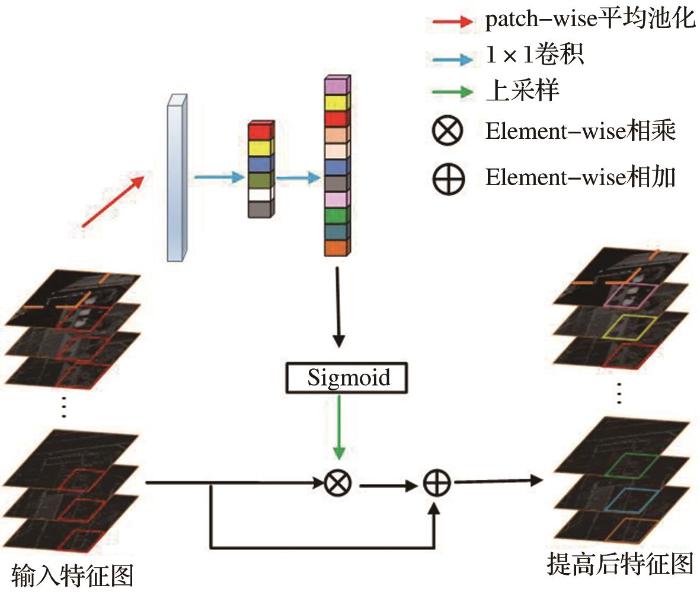
GCM+-LANet网络模型是以FCN作为分割框架,在LANet的基础上加入了GCM+模块,并将RestNet50的BottleNeck残差模块激活层的激活函数用FReLU替换,主要有两个并行分支来处理来自不同层的特征(如图3所示)。在上层分支中,经过ResNet50生成的高层特征通过PAM增强其特征表示;在下层分支中,卷积生成的低层特征首先通过PAM进行特征增强,然后通过AEM从高层嵌入语义信息。在PAM和AEM模块后都连接一个GCM+模块,获取全局上下文信息。
图3
2.2.1 GCM+
目前语义分割网络主要遵循定位优先的设计原则,对于分类任务是次优的。遥感图像的地物尺寸分布不均衡,有的地物尺寸大,有的地物尺寸小。在同样大小的感受野中,小尺寸的地物能被全部覆盖,但是大尺寸的地物不能完全被覆盖,提取大尺寸地物的空间上下文信息不丰富,导致分类效果不是很好。
针对以上问题提出了GCM+,该模块遵循以下两个设计原则:①从定位的角度来看,模型结构应该用全卷积来保留位置信息,且不使用全连接层或全局池化层,因为这些层会丢失部分信息;②从分类的角度来看,网络体系结构中应采用尽可能大的卷积核,以实现特征图和每个像素分类器之间的密集连接,使分类网络具备更强的分类能力来应对各种变换。
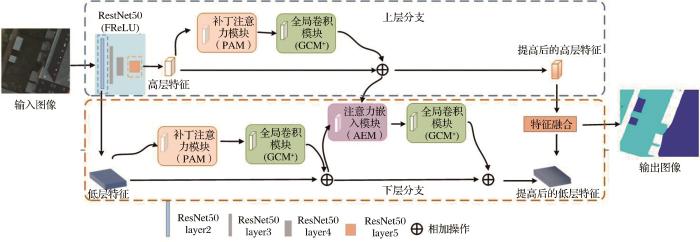
基于以上两个设计原则,GCM+采用k×1+1×k、1×1+1×1和1×k+k×1的组合卷积,而不是直接使用较大的卷积核与特征图进行密集连接。如图4所示,GCM+模块中的参数h和参数w分别是输入特征图的长和宽、参数c代表输入特征图的通道数、参数n代表实验数据集总类别数、参数k为每个卷积的卷积核大小。
图4
GCM+模块中特征图相加操作过程为:将经过P1分支和P2分支的特征图进行加和操作P1+P2,相加后的结果再与经过P3分支得到的特征图进行加和操作,加和操作后的输出为模块特征图。GCM+模块扩大了感受野,提高了目标物体的定位精度,从而能对目标物体进行更精确的分类。
2.2.2 FReLU
图5
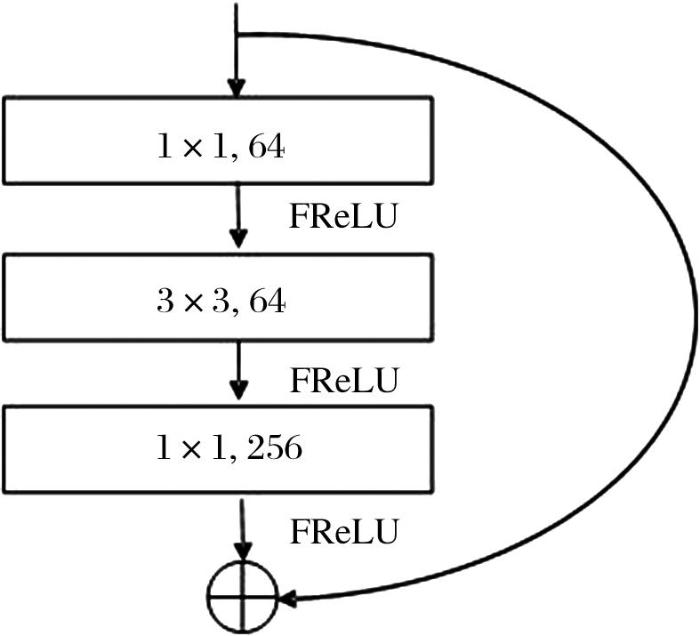
图6
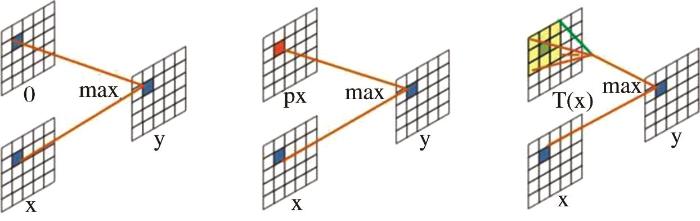
图6
ReLU、PReLU和FReLU激活函数
(a)ReLU (b)PReLU (c)FReLU
Fig.6
ReLU, PReLU and FReLU activation functions
ReLU和PReLU的形式分别为
遥感图像分辨率大、背景复杂,许多小目标容易被视为背景噪声而出现漏分的现象。FReLU引进了将空间上下文信息作为非线性函数条件的方法,能有效地改善错分、漏分的现象,提高遥感图像语义分割的精度。
3 实 验
3.1 数据与研究区
使用ISPRS数据集[25]中Potsdam区域的城市高分辨率遥感图像作为研究区数据进行实验,该数据集共有38幅图像,所有的图像大小都是6 000×6 000像素。Potsdam区域中有6种土地类别(图7),分别是不透水的表面、建筑物、低植被、树木、汽车和杂类/背景,杂类/背景主要包括水体和已定义为类别之外的地物,这些地物通常属于城市场景中不感兴趣的语义对象。为得到充足的实验数据,实验开始前对数据集进行了预处理,主要为图像切割和数据增强。将数据集中的图像均匀切割成512×512像素大小的图像,并对图像进行水平翻转和垂直翻转来进行数据增强。过滤掉一些标签存在问题的图像后,按照6∶2∶2的比例将数据集划分成训练集、验证集和测试集。
图7

3.2 实验环境与超参数设置
实验采用Pytorch深度学习框架,使用一块NVIDIA GeForce GTX 1080 Ti显卡。实验的各项参数设置有:batch size设置为2,学习率设置为0.025,epochs设置为400,momentum设置为0.9,使用随机梯度下降(Stochastic Gradient Descent,SGD)优化算法进行优化训练。
3.3 模型评价指标
遥感图像语义分割实际上还是分类任务,预测的结果也有4种情况,分别是:真正例(True Positive,TP)、假正例(False Positive,FP)、真负例(True Negative,TN)和假负例(False Negative,FN)。其中TP为预测结果中属于该类的实际也为该类的像素数量;FP为预测结果中属于其他类别而实际为该类的像素数量;TN为预测结果中属于其他类的而实际也为其他类的像素数量;FN为预测属于该类而实际为其他类别的像素数量。
采用像素准确率(Pix Accuracy,PA)、F1值和平均交并比(Mean Intersection over Union,MIoU)作为模型评价指标,其公式如下:
PA表示预测类别正确的像素占总像素的比例。
F1值的定义为精确率和召回率的调和平均值。
MIoU由于具有代表性成为语义分割的重要的标准度量指标。MIoU将基于类计算的交并比IoU进行累加,再进行平均,得到图像的全局评价。
其中:
3.4 实验结果与分析
3.4.1 分割精度分析
为了验证本文方法的有效性,与FCN[8]、U-Net[10]、SegNet[11]、LANet[19]、DeepLab V3+[15]、Coordinate Attention[20]等典型网络模型进行对比,各方法的评价指标如表1所示。从表1可以看出,相较于FCN、DeepLab V3+等经典的语义分割网络来说,基于局部补丁注意的网络模型LANet的PA能达到91.83%、F1能达到77.29%、MIoU能达到70.19%,后两个指标结果与经典的语义分割方法相比都略占优势,所以本文方法GCM+-LANet网络模型是在LANet上进行改进的。由于FCN、DeepLab V3+等对比网络特征提取时采用的是3×3大小卷积核,为了更好地进行对比,在对比实验过程中GCM+-LANet网络中GCM+模块的参数k也设置为3。此时,GCM+-LANet网络的PA达到了94.42%、F1达到了80.99%、MIoU达到了75.27%,比基础网络LANet分别提高了2.59%、3.7%和5.08%。
表1 不同方法在Potsdam数据集上的分割精度
Table 1
| 网络模型 | PA/% | F1/% | MIoU/% |
|---|---|---|---|
| FCN | 92.40 | 77.21 | 70.09 |
| U-Net | 91.82 | 77.05 | 69.98 |
| SegNet | 91.55 | 75.92 | 68.62 |
| LANet | 91.83 | 77.29 | 70.19 |
| DeepLab V3+ | 86.99 | 68.14 | 59.34 |
| Coordinate Attention | 90.94 | 75.45 | 67.94 |
| GCM+-LANet(k=3) | 94.42 | 80.99 | 75.27 |
3.4.2 效果图分析
为了能更好突出本文方法的可行性,如图8所示,分别选取了6个有代表性的场景进行分析。其中场景1有边界规则的建筑物,用来探究网络在细化分割边界的效果;场景2有小的和细长的地物类别,用来探究小目标和细长目标的分割性能;场景3是有大尺寸的地物,用来探究网络对于大尺寸目标的分割能力。场景6有较明显明暗区域,用于分析受阴影影响网络的分割性能。
图8
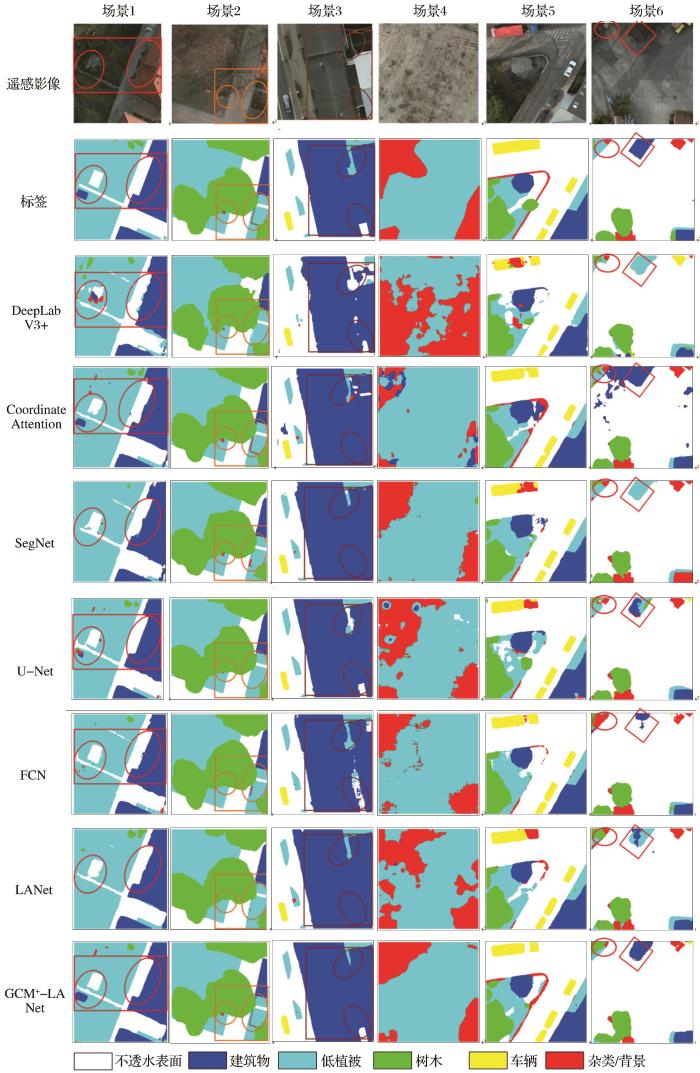
图8
不同网络模型在Potsdam数据集上的预测结果对比
Fig.8
Comparison of prediction results of different network models of Potsdam dataset
分析图8的效果图细节,对于场景1,从左边圆圈框住的区域看,DeepLab V3+、SegNet、U-Net、FCN和LANet均未检测出建筑物,GCM+-LANet和Coordinate Attention则能成功检测出建筑物。从右边圆圈框住的区域看,DeepLab V3+、Coordinate Attention、SegNet、FCN和LANet建筑物的边界比较粗糙,而GCM+-LANet和U-Net的分割边界则比较平整,说明GCM+-LANet加入的GCM+和FReLU能提高分类能力和细化边界。场景2的两个圆圈区域中GCM+-LANet和Coordinate Attention能将小的和细长的地物类别分割出来,说明GCM+-LANet中加入FReLU,利用将空间上下文作为非线性函数的条件,在特征提取时能更好地利用上下文信息。从场景3中的矩形框和上下两个圆圈区域可以看出,只有GCM+-LANet能将大面积的建筑物形状给正确的分割出来,而且还不产生多余的噪声点,表明GCM+模块使用多卷积组合扩大感受野,能提升大尺寸地物类别的分类性能。从场景4和场景5中看,只有GCM+-LANet网络分割出来的结果图最接近标注的标签图,进一步验证了本文方法的有效性。
从场景6的矩形框来看,当地物受阴影遮挡时,FCN、U-Net等语义分割网络会将它错分为低植被这一类,GCM+-LANet则能正确将它分为建筑物一类。但是,从场景6中的圆形框来看,在受阴影的影响下,GCM+-LANet对易混淆的地物(如图中的低植被和树木)也会出现轻微地错分现象。所以GCM+-LANet对阴影影响有较好的容忍性,但还需要进一步提高。
3.4.3 GCM+模块参数k值分析
GCM+模块实现了分类器和特征图之间的密集连接,其参数设置分别为:w=16、h=16、c=128和n=6,因此只需对参数k进行讨论。GCM+的核心思想是使用大内核,其大小由参数k决定,k的取值将会直接影响分割结果。为了进行验证,实验中分别将k设置为3、5、7、9、11、13、15。当k=15时GCM+模块近似于16×16大小的特征图,此时网络就变成了真正的全局卷积结构。
从图9的趋势折线图来看,当k=3时,GCM+-LANet网络模型预测的MIoU为75.27%、参数量为24.42 MB,随着k值的增大MIoU值缓慢提升,到k=15时,预测的MIoU达到了75.83%、参数量达到了25.6 MB。模型的性能随着k值的增加而提升,但是产生的参数量也越大。
图9
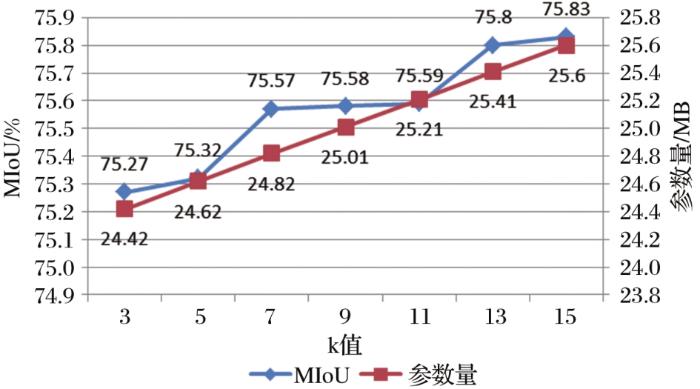
图9
k值对MIoU和参数量的影响分析
Fig.9
Analysis of the influence of k on MIoU and parameter number
4 讨 论
一直以来,精确分割大尺寸和细小地物目标是高分辨率遥感图像语义分割的技术难点。鉴于此,实验分别采用GCM+模块和FReLU激活函数来提升分割精度,并与其他经典的语义分割网络结果对比,研究发现:①GCM+模块因使用3分支形成组合卷积结构扩大感受野,使得分类器对大尺寸地物目标有足够大的密集连接范围,能提取更完整的语义信息,能更精确地定位大尺寸地物目标的边界;②FReLU激活函数由于将空间上下文信息作为非线性函数条件,能减少将细小的地物目标视为背景噪声的分割情况,降低了细小目标漏分的情况。其他经典的语义分割网络结果中,SegNet和U-Net对规则的大尺寸目标也有较好的分割效果,但有时候对细长、小尺寸和不规则大尺寸目标分割效果不是很好。而Coordinate Attention利用将位置信息嵌入到通道注意力的方法增强上下文信息提取,能较准确地分割出细长和小尺寸地物目标,但是可能会产生其他多余的噪声点且难以完整地分割出不规则大尺寸地物。
GCM+模块中参数k的值会直接影响分割结果,模型预测的MIoU会随着k值的增大而增大。这是因为当k值增加时,组合卷积有更大的感受野,与分割对象进行更大范围的密集连接,提取更丰富的语义信息。
值得注意的是,实验是基于深度学习的方法对遥感图像语义分割研究问题开展开研究,虽然取得了一定的研究成果,但仍存在需要改进和完善的地方:由于实验采用全监督的方式进行网络训练,因此训练过程中需要大量的高质量样本数据,并且该样本数据难以获取。针对这一问题,未来的工作可以研究半监督或弱监督的方法,并将其运用于高分辨率遥感图像语义分割。
5 结 语
为了提高高分辨率遥感图像语义分割精度,实验基于LANet模型提出了GCM+-LANet模型,设计了1×k+k×1、1×1+1×1和k×1+1×k组合卷积构成GCM+模块加入到网络模型中,另外还引入一种新的激活函数FReLU以改善网络模型。GCM+-LANet在大尺寸地物、小尺寸和细长的地物上都能达到更好的分割效果,比基础网络LANet在PA、F1和MIoU上分别提高了2.59%、3.7%和5.08%。
参考文献
Large kernel matters-improve semantic segmentation by global convolutional network
[C]∥
The Global K-means clustering algorithm
[J].
Blobworld: Image segmentation using expectation-maximization and its application to image querying
[J].
The decisiontree classification and its application research in land cover
[J].
决策树分类法及其在土地覆盖分类中的应用
[J].
Road extraction using SVM and image segmentation
[J].
A simple, fast, and accurate algorithm to estimate large phylogenies by maximum likelihood
[J].
Machine learning: Trends, perspectives, and prospects
[J].
Comparison of machine learning methods for land use/land cover classification in the complicated terrain regions
[J].
复杂地形区土地利用/土地覆被分类机器学习方法比较研究
[J].
Fully convolutional networks for semantic segmentation
[C]∥
Context encoding for semantic segmentation
[C]∥
U-Net: convolutional networks for biomedical image segmentation
[C]∥
Segnet: A deep convolutional encoder-decoder srchitecture for image segmentation
[J].
Semantic image segmentation with deep convolutional nets and fully connected CRFs
[EB/OL].
Deep lab: Semantic image segmentation with deep convolutional nets, atrous convolution, and Fully Connected CRFs
[J].
Rethinking atrous convolution for semantic image segmentation
[EB/OL].
Encoder decoder with atrous separable convolution for semantic image segmentation
[C]∥
Semantic segmentation using deep learning with vegetation indicesfor rice lodging identification in multi date UAV visible Images
[J].
An ensemble architecture of deep convolutional segnet and U-Net networks for building semantic segmentation from high resolution aerial images
[J].
Road extraction by using atrous spatial pyramid pooling integrated encoder decoder network and structural similarity loss
[J].
LANet: Local attention embedding to improve the semantic segmentation of remote sensing images
[J].
Coordinate attention for efficient mobile network design
[C]∥
Funnel activation for visual recognition
[C]∥
Deep residual learning for image recognition
[C]∥
Squeeze and excitation networks
[C]∥
Results of the ISPRS benchmark on urban object detection and 3D building reconstruction
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}