1 引 言
视觉问答[1 -2 ] (Visual Question Answering,VQA)结合计算机视觉(Computer Vision,CV)、自然语言处理(Neural Language Processing,NLP)[3 -4 ] 和关系推理等多种人工智能技术[5 -6 ] ,是一个多模态任务,其旨在对输入的图片和相关问题做出正确回答[7 ] 。近些年伴随着CV和NLP的发展,VQA研究[8 -9 ] 取得了巨大的进步,为广告服务、视障助理[10 ] 、系统互交等提供了诸多便利。
在遥感领域中,遥感影像在土地利用、灾害管理、城市规划等资源监测中发挥重要作用[11 -12 ] 。然而,现有的VQA研究多集中于自然图像,而自然图像由于存在景深和虚化的关系,人们往往只关注图像中的显著性目标,忽略全局性场景。但在遥感影像中,所有目标均在同一焦平面,因此对于全局场景的理解和局部目标的识别同样重要。这种从全局到局部的尺度变化令传统VQA模型难以直接迁移至遥感图像中,为遥感VQA研究带来了新的挑战。文中从遥感VQA的实际需求出发,解决遥感影像VQA中的尺度变化问题,设计多尺度遥感影像VQA的数据集和模型。
近年来,视觉问答在遥感领域也有少量研究成果[13 -16 ] 。2020年Lobry等[13 ] 采用自动生成标签的方式首次构造了一个应用于遥感VQA的数据集并命名为RSVQA,RSVQA中的图像来自于OpenStreetMAp数据和Sentinel-2数据,问答设计利用原始图像提取图像特征以及属性,根据问题模板选择生成正确答案,在问题设计上仅有5类对象属性问题(如:计数,比较,存在性,面积,城市或郊区)等。2021年Maryam等[14 ] 提出了一个命名为FloodNet的数据集,该数据集为洪水过后的高分辨率航空遥感影像,分别设计了遥感图像分类、语义分割和视觉问答三大性能,其中VQA部分数据集问答模式有三种类型,关于计数、关于整张图像的情况以及yes/no 类型问答。Yuan等[15 ] 提出了一组适用于遥感变化检测的遥感VQA数据集CDVQA,该数据集以现有的变化检测数据集为基础,自动生成CDVQA数据集,CDVQA问答类型针对区域变化情况进行提问。
然而这些现存的遥感VQA数据集类型较少,RSVQA数据集较大但问答模式单调仅有5种问答类型, FloodNet和CDVQA数据集为专题场景遥感VQA数据集,只适用于特定场景如洪水灾害和变化检测,这些数据集难以满足不同场景下对遥感图像应用的需求。遥感图像场景复杂并且目标之间尺寸差异大,单一的尺度难以提取遥感图像尺度差异巨大的目标特征,所以遥感图像特征提取中的多尺度语境信息非常重要。虑到遥感图像在实际应用中的价值,为了能够实现对不同尺度的遥感影像中的信息充分利用,快速响应涉及问答的遥感场景需求,本研究创建了一组新的遥感VQA数据集“MRS-VQA数据集”,并提出了多尺度特征融合法的遥感VQA模型“MRS-VQA模型”。MRS-VQA数据集问答对从全局到局部的不同尺度特征进行问答设计。问答对紧扣图像内容,避免无效问答和简单问答,有效减少了标签的冗余度。MRS-VQA模型在图像提取模块使用VGG-16网络结构,利用多尺度特征融合法提取图像特征,分别提取大尺度、中尺度和小尺度3个尺度的特征图,然后使用连接将3个尺度特征进行融合,得到一个具有多尺度特性的特征图。并利用LSTM提取文本特征,在多模态融合部分使用两层注意力,使模型可视化,增强模型的可解释性,有效提升了模型的准确率。
2 数据集
2.1 MRS-VQA数据集创建
MRS-VQA数据集中的图像来源于遥感分类影像AID数据集[17 ] ,该数据集包含30个不同的场景,包括机场、裸地、棒球场、海滩、桥梁、行政中心、教堂、商业区、密集住宅、沙漠、农田、森林、工业区、草坪、中型住宅、山地、公园、停车场、游乐场、池塘、港口、火车站、度假村、河流、学校、稀疏住宅、广场、体育场、蓄水池、高架桥。每个场景约230张大小为600×600像素的图像,图像分辨率在0.5 m~8 m之间,本文从每个场景中随机选取100张图像作为本文的图像数据源,共计3 000张影像。
在问题创建阶段,为保证每个问题的质量,所有问题均为专家手工标注,所提出的问题与图像的局部目标或全局场景相关,文本标注过程中,对每张图像提问一个问题并回答一个标准答案。标注的问题涉及场景、主题、对象、颜色、形状、数量等。如图1 所示,同一个类别的图像用多种不同方式进行提问,以保证问题样本的多样性和丰富度。图中蓝色字体为针对局部目标的问题,红色字体为针对全局场景提出的问题。最终获得3 000个样本,即图像、问题、答案对。实验过程中,训练集占70%,验证集占20%,测试占10%。
图1
图1
MRS-VQA数据集样本
Fig.1
Samples in MRS-VQA dataset
2.1 数据集分析
唯一性分析:本文研究中,MRS-VQA数据集中有3 000张影像,3 000个问答对,其中问题类型有399个,答案类型有120个,唯一性分析体现了数据集问答的多样性。
(1)长度分析:问题平均长度为7.6个单词,大部分问题有8个单词,问题最大长度为17个单词。同样,答案平均长度为1.3,大多数答案只有一个单词,答案最多有3个单词。长度分布结果反应了MRS-VQA数据集问答对的复杂性。
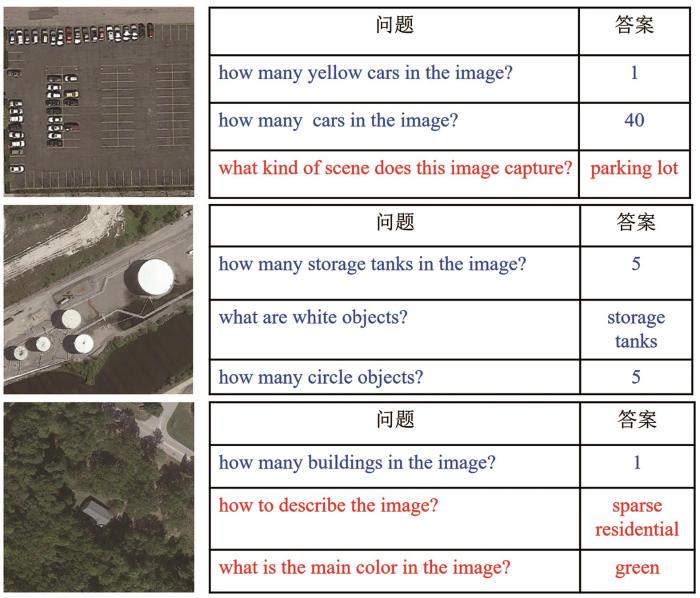
(2)单词类型分析:问题中一些关键词可以表征其是全局问题或局部问题。例如“scene”和“theme”暗示问题和图像全局内容,而“object”和“many”则暗示图像中的局部特征。图2 统计了一些关键的单词出现的频率。从图2 中可以看出,表示全局特征问题的单词“scene”、“theme”和“show”’占总数量的56.12%,局部特征问题中出现的单词“many”、“object”和“building”占39.76%,以其他方式提问的低频局部问题单词“others”占比10.30%。在总体来说,全局问题与局部问题数量大致相同。
图2
图2
问题关键字频率分布
Fig.2
Frequency distribution of question keywords
(3)与其他数据集比较:从表1 中可以看到,目前遥感VQA数据集较少,与其他遥感VQA数据集相比,该数据集具有以下优点:①场景的多样性,MRS-VQA数据集中包含30个不同场景的影像,场景类型丰富,场景数量远多于其他数据集;②专业问题的设计,RSVQA、CDVQA数据集均使用模板生成方式标注问题,问答模式单调刻板,模板未能准确反映图像真实内容,而该数据集是不同专业背景专家手工标注,这些专家分别来自地理学、测绘学、遥感和地信,而不是使用简单的问题模板,每个问题都是都针对图像局部目标或全局场景进行标注,问答模式紧扣图像内容。③语言偏见少,为了减少语言偏见,避免提出二元问答对(指只有两种固定答案的问答方式,如yes/no, true/false回答的问题),并使用不同的表达来描述相似的图像。据统计分析,有318个不同类型的问题(80%)出现的频率小于5次,而在RSVQA中存在很大的不平衡,比如对于RSVQA中的数值答案“0”占所有数值答案的比例为60.9%,这种较大的语言偏差会降低模型的鲁棒性。FloodNet数据集为飓风过后洪水受灾影像,影像场景单一,问答类型较少,只针对计数、yes/no以及整幅影像情况进行提问,问答模式简单。
以上比较发现,本文的数据集场景复杂,问答模式多样化,问答针对局部目标和全局场景进行提问,更加贴合图像的真实情况。
3 研究方法
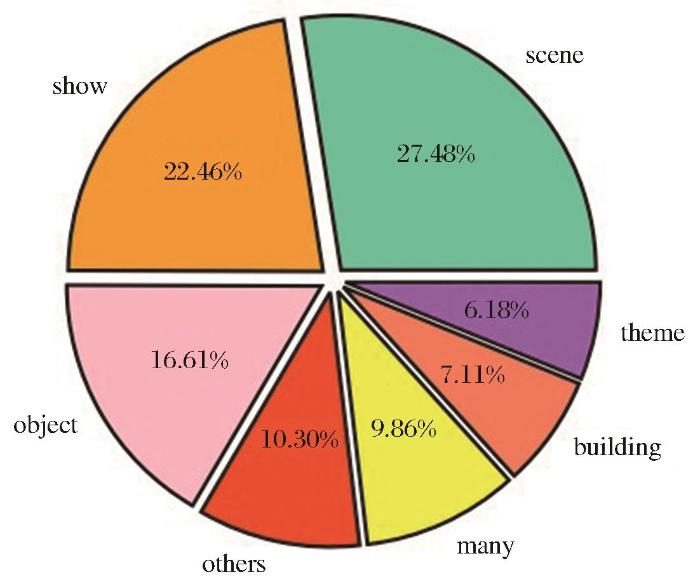
本文提出一种多尺度遥感视觉问答(MRS-VQA)模型,该模型结合了图像模块中的多尺度特征,以解决图像中尺度变化的影响。模型结构如图3 所示。图像模块使用卷积神经网(CNN)提取图像特征,并用循环神经网络(RNN)提取文本特征,在融合模块使用注意力机制,答案预测模块视为一个分类过程[18 -21 ] ,最后使用s o f t m a x
图3
图3
MRS-VQA模型框架
Fig.3
Framework of the proposed MRS-VQA model
图像模块:图像模块用CNN获取图像的初始特征。CNN已经成为一种功能强大的图像特征提取器,VGG-16[22 ] 作为CNN中最经典的图像特征提取器之一,其强大的特征提取能力能够在各种任务中表现出色的性能[23 -25 ] 。因此,为了解决遥感图像中目标的多样性和尺寸差异问题,本文以VGG-16网络主干为基准,提取多尺度特征图。VGG-16网络中有5个尺寸不同的ConvBlock模块,前两个模块中每个模块有两个卷积层,后三个模块中每个模块有三个卷积层,我们选择后三个模块中的最后一个卷积提取的特征图,因前两个模块总共只有四层卷积,网络层数较浅,学习到的有效信息较少且数据冗余较大,因此选择的是后三个模块,得到三个具有不同尺度的特征图。首先输入大小为448×448像素大小的图像,模型使用VGG-16中的第三(ConvBlock3大尺度)、第四(ConvBlock4中尺度)和第五(ConvBlock4小尺度)块中的最后一层卷积提取图像特征,特征图大小分别为112×112×256、56×56×512、28×28×512像素,获得3个具有最大尺度差异组合的不同尺度特征,然后将这三个不同尺度的特征合并为一个融合特征,并以张量形式输出。这样既能充分利用原始图像的语义信息也能够避免过多特征融合造成的数据冗余。该过程可以用公式(1)描述:
F I = { F I 1 , F I 2 , . . . , F I t } = f l a t t e n ( C o n v ( I ) )
其中:F I t ∈ R D , t ∈ { 0,1 , . . . , t } I t
问题模块:为了理解和表示问题的语义信息,本模块使用两层长短记忆网络(LSTM)[26 ] 来处理输入的问题Q Q = [ q 1 , q 2 , . . . , q n ] W [ ⋅ ] q n Q 公式(3)获取输入的问题特征。
E Q = [ W [ q 1 ] , W [ q 2 ] , . . . , W [ q n ] , 0 , . . . , 0 ] ]
F Q = L S T M ( E Q )
其中:E Q F Q
融合与答案预测模块:融合模块对图像特征和问题特征进行融合,得到具有双模态的注意力特征向量,然后使用s o f t m a x
V ( F I , F Q ) = s o f t m a x ( t a n h ( F I ) + t a n h ( F Q ) )
公式(4)中,V ( ⋅ ) t a n h F Q s o f t m a x
A = s o f t m a x ( c o n v ( c o n v ( v ) ) )
其中:A
4 实验结果与分析
探究VQA模型中注意力对MRS-VQA数据集的影响,将结果进行可视化(如图5 ),有助于理解模型的推理过程。此外,还评估了不同模型的定性结果,以验证本方法的有效性。
图4
图4
不同模型的可视化结果
Fig.4
Visualization results of different models
图5
图5
注意力机制可视化((ai)原始图像;(bi)注意力图像)
Fig.5
Visualization of the attention mechanism
4.1 实验数据与平台
本实验中,为了验证MRS-VQA数据集的有效性,将MRS-VQA数据集分别在我们的模型MRS-VQA与RSVQA模型上进行训练和验证。RSVQA模型使用ResNet-152[27 ] 提取图像特征,文本模块使用skip-thoughts[28 ] ,特征融合模块采用简单向量点乘方式,答案预测以分类的方式输出答案。
遥感视觉问答模型在训练过程中需要进行大量的运算,模型需在GPU中运行,以提高运行速率。本文在TensorFlow框架,采用Python3.6撰写程序,操作系统为Ubuntu16.04,CPU为Inter(R)Xeon(R)E5-2620v3,GPU为TeslaK80内存为11G,同时采用CUDA9.0与CuDNN7.5.2进行加速处理。
4.2 实验参数设置
本实验基于TensorFlow深度学习框架进行,采用AdamOptimizer优化器,学习率设为。模型训练40个epoch,每个epoch的batch size设置为8。LSTM的维数和注意力大小分别设置为512和2 048。实验中将dropout rate设置为0.5,以缓解训练阶段的过拟合问题。在对比实验RSVQA模型中,将得到的图像特征向量和问题向量数值均设置为2 048,其他训练参数设置不变。
4.3 实验结果
基于MRS-VQA数据集,分别在MRS-VQA模型和RSVQA模型上进行验证,模型精度结果如表2 所示。相比于RSVQA模型,集成不同尺度视觉特征的MRS-VQA方法取得了更高的精度,这说明基于注意力的多尺度特征融合机制可以更好的解决尺度变化对遥感影像的影响,而RSVQA模型在提取和细化局部尺度特征时忽略了这一点。结果对比输出如图4 所示。
从图4 可以发现,本方法在不同类型问题(a~f)中均能正确预测答案,对于局部小目标物也能充分识别(f),能够结合目标背景信息准确推断答案(d),特别是在图像中只有场景,没有任何物体时,也能精准推断答案(e),这表明了本文提出的MRS-VQA模型具有较强的鲁棒性和适应性,在复杂的图像场景下能够准确预测答案。对于有明显地物的影像,RSVQA模型能正确预测答案(a)~(c),但对于复杂背景(d)无明显地物(e)以及小目标的图像预测效果较差,虽然答案与图像相关,但预测错误,而我们的模型能够正确预测答案。这主要是MRS-VQA模型在图像特征提取中使用了多尺度特征融合信息以及多模态融合中使用了注意力机制,有效提高了模型的准确率。注意力权重通过对图像特征进行筛选,重点关注目标特征区域,并摒弃冗余特征和噪声信息,增强模型对遥感图像内容的理解和推理,提升答案预测的准确性。
此外,我们使用RSVQA低分辨率数据集来进一步验证模型。实验参数不变的情况下, RSVQA数据集在MRS-VQA模型上表现更好,这也充分说明了MRS-VQA模型的有效性。
4.4 注意力结果可视化
图5 为MRS-VQA模型注意力可视化结果图,图5 中4组图片中每组分别有两张影像,左边为原始影像,右边为加入注意力后模型可视化结果。图中亮度高的地方说明对该区域特征关注度较高。其中(a1 )和(a2 )是针对局部目标提问,(a3 )和(a4 )是针对全局场景进行提问。从图5 中可以看到,当我们对图像中的局部目标提问时,模型能够根据问题中的关键词定位到图像中的关键局部区域,而当我们对全局场景提问时,注意力则均匀分布在整张图像上。注意力可视化实验结果表明该模型能够准确定位到问题所对应的图像内容,进而推断出二者之间的交互推理关系。
5 结 论
本文设计了一个新的遥感VQA数据集MRS-VQA数据集,该数据集包含3 000个样本,在MRS-VQA数据集的基础上,本文提出了一种在图像模块中嵌入多尺度融合特征结构的MRS-VQA模型,用于组合不同尺度的图像特征。在文本处理方面,采用LSTM提取问题特征,用两个注意力层融合图像特征和文本特征。最后,将融合特征输入到s o f t m a x
参考文献
View Option
[1]
FANG H GUPTA S IANDOLA F et al From captions to visual concepts and back
[C]∥Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition , June 07-12, 2015 , Boston, MA, USA . New York : IEEE , 2015 :1473 -1482 .
[本文引用: 1]
[2]
CHEN X ZITNICK C L Learning a recurrent visual representation for image caption generation
[J]. arXiv preprint arXiv:, 2014 .
[本文引用: 1]
[3]
DONAHUE J ANNE HENDRICKS L Guadarrama S et al Long-term recurrent convolutional networks for visual recognition and description
[C]∥Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition , June 07-12,2015 , Boston, MA, USA . New York : IEEE , 2015 : 2625 -2634 .
[本文引用: 1]
[4]
MAO J XU W YANG Y et al Explain images with multimodal recurrent neural networks
[J]. arXiv preprint arXiv:, 2014 .
[本文引用: 1]
[5]
KIROS R SALAKHUTDINOV R ZEMEL R S Unifying visual-semantic embeddings with multimodal neural language models
[J]. arXiv preprint arXiv:, 2014 .
[本文引用: 1]
[6]
KARPATHY A FEI-FEI L Deep visual-semantic alignments for generating image descriptions
[C]∥Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition , June 07-12, 2015 , Boston, MA, USA . New York : IEEE , 2015 : 3128 -3137 .
[本文引用: 1]
[7]
ANTOL S AGRAWAL A LU J et al Vqa: Visual question answering
[C]∥Proceedings of 2015 IEEE International Conference on Computer Vision , December 7-13, 2015 , Santiago, Chile . New York : IEEE , 2015 :2425 -2433 .
[本文引用: 1]
[8]
GOYAL Y KHOT T SUMMERS-STAY D et al Making the v in vqa matter: Elevating the role of image understanding in visual question answering
[C]∥Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition , July 21-26, 2017 , Honolulu, HI, USA . New York : IEEE , 2017 :6904 -6913 .
[本文引用: 1]
[9]
GURARI D LI Q STANGL A J et al Vizwiz grand challenge: Answering visual questions from blind people
[C]∥Proceedings of 2018 IEEE Conference on Computer Vision and Pattern Recognition , June 18-23, 2018 , Salt Lake City, UT, USA . New York : IEEE , 2018 :3608 -3617 .
[本文引用: 1]
[10]
BIGHAM J P JAYANT C JI H et al Vizwiz: nearly real-time answers to visual questions
[C]∥Proceedings of the 23nd Annual ACM Cymposium on User Interface Software and Technology , October 3-6, 2010 , New York, New York, USA . New York : ACM , 2010 : 333 -342 .
[本文引用: 1]
[11]
LU X GONG T ZHENG X Multisource compensation network for remote sensing cross-domain scene classification
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2019 , 58 (4 ): 2504 -2515 .
[本文引用: 1]
[12]
LU X WANG B ZHENG X Sound active attention framework for remote sensing image captioning
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2019 , 58 (3 ): 1985 -2000 .
[本文引用: 1]
[13]
LOBRY S MARCOS D MURRAY J et al RSVQA: Visual question answering for remote sensing data
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2020 , 58 (12 ): 8555 -8566 .
[本文引用: 2]
[14]
RAHNEMOONFAR M CHOWDHURY T SARKAR A et al Floodnet: A high resolution aerial imagery dataset for post flood scene understanding
[J]. IEEE Access , 2021 , 9 : 89644 -89654 .
[本文引用: 1]
[15]
YUAN Z MOU L XIONG Z et al Change detection meets visual question answering
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2022 , 60 : 1 -13 .
[本文引用: 1]
[16]
GUO Y HUANG Y Capturing Global and Local Information in Remote Sensing Visual Question Answering
[C]∥IGARSS 2022-2022 IEEE International Geoscience and Remote Sensing Symposium . IEEE , 2022 : 6340 -6343 .
[本文引用: 1]
[17]
XIA G S HU J HU F et al AID: A benchmark data set for performance evaluation of aerial scene classification
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2017 , 55 (7 ): 3965 -3981 .
[本文引用: 1]
[18]
YANG Z HE X GAO J et al Stacked attention networks for image question answering
[C]∥Proceedings of 2016 IEEE conference on computer vision and pattern recognition , June 27-30, 2016 , Vegas, NV, USA . New York : IEEE , 2016 : 21 -29 .
[本文引用: 1]
[19]
ILIEVSKI I YAN S FENG J A focused dynamic attention model for visual question answering
[J]. arXiv preprint arXiv:, 2016 .
[20]
XU H Ask SAENKO K. attend and answer: Exploring question-guided spatial attention for visual question answering
[C]∥European Conference on Computer Vision . Springer , Cham, October 8-18, 2016 , Amsterdam, Netherlands . 2016 :451 -466 .
[21]
SHIH K J SINGH S HOIEM D Where to look: Focus regions for visual question answering
[C]∥Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition , June 27-30, 2016 , Vegas, NV, USA . New York : IEEE , 2016 : 4613 -4621 .
[本文引用: 1]
[22]
SIMONYAN K ZISSERMAN A Very deep convolutional networks for large-scale image recognition
[J]. arXiv preprint arXiv:, 2014 .
[本文引用: 1]
[23]
ZHU R ZHANG S WANG X et al ScratchDet: Training single-shot object detectors from scratch
[C]∥Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition , June 15-20, 2019 , Long Beach, CA, USA . New York : IEEE , 2019 :2268 -2277 .
[本文引用: 1]
[24]
LIN S JI R YAN C et al Towards optimal structured cnn pruning via generative adversarial learning
[C]∥Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition , June 15-20, 2019 , Long Beach, CA, USA . New York : IEEE , 2019 :2790 -2799 .
[25]
LIU J J HOU Q CHENG M M et al A simple pooling-based design for real-time salient object detection
[C]∥Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition , June 15-20, 2019 , Long Beach, CA, USA . New York : IEEE , 2019 :3917 -3926 .
[本文引用: 1]
[27]
HE K ZHANG X REN S et al Deep residual learning for image recognition
[C]∥Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition ,June 27-30, 2016 ,Las Vegas,NV,USA .New York :IEEE ,2016 :770 -778 .
[本文引用: 1]
[28]
KIROS R ZHU Y SALAKHUTDINOV R R et al Skip-thought vectors
[J]. Advances in neural information processing systems , 2015 :28 . DOI: arxiv.org/abs/1506.06726
[本文引用: 1]
From captions to visual concepts and back
1
2015
... 视觉问答[1 -2 ] (Visual Question Answering,VQA)结合计算机视觉(Computer Vision,CV)、自然语言处理(Neural Language Processing,NLP)[3 -4 ] 和关系推理等多种人工智能技术[5 -6 ] ,是一个多模态任务,其旨在对输入的图片和相关问题做出正确回答[7 ] .近些年伴随着CV和NLP的发展,VQA研究[8 -9 ] 取得了巨大的进步,为广告服务、视障助理[10 ] 、系统互交等提供了诸多便利. ...
Learning a recurrent visual representation for image caption generation
1
2014
... 视觉问答[1 -2 ] (Visual Question Answering,VQA)结合计算机视觉(Computer Vision,CV)、自然语言处理(Neural Language Processing,NLP)[3 -4 ] 和关系推理等多种人工智能技术[5 -6 ] ,是一个多模态任务,其旨在对输入的图片和相关问题做出正确回答[7 ] .近些年伴随着CV和NLP的发展,VQA研究[8 -9 ] 取得了巨大的进步,为广告服务、视障助理[10 ] 、系统互交等提供了诸多便利. ...
Long-term recurrent convolutional networks for visual recognition and description
1
2015
... 视觉问答[1 -2 ] (Visual Question Answering,VQA)结合计算机视觉(Computer Vision,CV)、自然语言处理(Neural Language Processing,NLP)[3 -4 ] 和关系推理等多种人工智能技术[5 -6 ] ,是一个多模态任务,其旨在对输入的图片和相关问题做出正确回答[7 ] .近些年伴随着CV和NLP的发展,VQA研究[8 -9 ] 取得了巨大的进步,为广告服务、视障助理[10 ] 、系统互交等提供了诸多便利. ...
Explain images with multimodal recurrent neural networks
1
2014
... 视觉问答[1 -2 ] (Visual Question Answering,VQA)结合计算机视觉(Computer Vision,CV)、自然语言处理(Neural Language Processing,NLP)[3 -4 ] 和关系推理等多种人工智能技术[5 -6 ] ,是一个多模态任务,其旨在对输入的图片和相关问题做出正确回答[7 ] .近些年伴随着CV和NLP的发展,VQA研究[8 -9 ] 取得了巨大的进步,为广告服务、视障助理[10 ] 、系统互交等提供了诸多便利. ...
Unifying visual-semantic embeddings with multimodal neural language models
1
2014
... 视觉问答[1 -2 ] (Visual Question Answering,VQA)结合计算机视觉(Computer Vision,CV)、自然语言处理(Neural Language Processing,NLP)[3 -4 ] 和关系推理等多种人工智能技术[5 -6 ] ,是一个多模态任务,其旨在对输入的图片和相关问题做出正确回答[7 ] .近些年伴随着CV和NLP的发展,VQA研究[8 -9 ] 取得了巨大的进步,为广告服务、视障助理[10 ] 、系统互交等提供了诸多便利. ...
Deep visual-semantic alignments for generating image descriptions
1
2015
... 视觉问答[1 -2 ] (Visual Question Answering,VQA)结合计算机视觉(Computer Vision,CV)、自然语言处理(Neural Language Processing,NLP)[3 -4 ] 和关系推理等多种人工智能技术[5 -6 ] ,是一个多模态任务,其旨在对输入的图片和相关问题做出正确回答[7 ] .近些年伴随着CV和NLP的发展,VQA研究[8 -9 ] 取得了巨大的进步,为广告服务、视障助理[10 ] 、系统互交等提供了诸多便利. ...
Vqa: Visual question answering
1
2015
... 视觉问答[1 -2 ] (Visual Question Answering,VQA)结合计算机视觉(Computer Vision,CV)、自然语言处理(Neural Language Processing,NLP)[3 -4 ] 和关系推理等多种人工智能技术[5 -6 ] ,是一个多模态任务,其旨在对输入的图片和相关问题做出正确回答[7 ] .近些年伴随着CV和NLP的发展,VQA研究[8 -9 ] 取得了巨大的进步,为广告服务、视障助理[10 ] 、系统互交等提供了诸多便利. ...
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
1
2017
... 视觉问答[1 -2 ] (Visual Question Answering,VQA)结合计算机视觉(Computer Vision,CV)、自然语言处理(Neural Language Processing,NLP)[3 -4 ] 和关系推理等多种人工智能技术[5 -6 ] ,是一个多模态任务,其旨在对输入的图片和相关问题做出正确回答[7 ] .近些年伴随着CV和NLP的发展,VQA研究[8 -9 ] 取得了巨大的进步,为广告服务、视障助理[10 ] 、系统互交等提供了诸多便利. ...
Vizwiz grand challenge: Answering visual questions from blind people
1
2018
... 视觉问答[1 -2 ] (Visual Question Answering,VQA)结合计算机视觉(Computer Vision,CV)、自然语言处理(Neural Language Processing,NLP)[3 -4 ] 和关系推理等多种人工智能技术[5 -6 ] ,是一个多模态任务,其旨在对输入的图片和相关问题做出正确回答[7 ] .近些年伴随着CV和NLP的发展,VQA研究[8 -9 ] 取得了巨大的进步,为广告服务、视障助理[10 ] 、系统互交等提供了诸多便利. ...
Vizwiz: nearly real-time answers to visual questions
1
2010
... 视觉问答[1 -2 ] (Visual Question Answering,VQA)结合计算机视觉(Computer Vision,CV)、自然语言处理(Neural Language Processing,NLP)[3 -4 ] 和关系推理等多种人工智能技术[5 -6 ] ,是一个多模态任务,其旨在对输入的图片和相关问题做出正确回答[7 ] .近些年伴随着CV和NLP的发展,VQA研究[8 -9 ] 取得了巨大的进步,为广告服务、视障助理[10 ] 、系统互交等提供了诸多便利. ...
Multisource compensation network for remote sensing cross-domain scene classification
1
2019
... 在遥感领域中,遥感影像在土地利用、灾害管理、城市规划等资源监测中发挥重要作用[11 -12 ] .然而,现有的VQA研究多集中于自然图像,而自然图像由于存在景深和虚化的关系,人们往往只关注图像中的显著性目标,忽略全局性场景.但在遥感影像中,所有目标均在同一焦平面,因此对于全局场景的理解和局部目标的识别同样重要.这种从全局到局部的尺度变化令传统VQA模型难以直接迁移至遥感图像中,为遥感VQA研究带来了新的挑战.文中从遥感VQA的实际需求出发,解决遥感影像VQA中的尺度变化问题,设计多尺度遥感影像VQA的数据集和模型. ...
Sound active attention framework for remote sensing image captioning
1
2019
... 在遥感领域中,遥感影像在土地利用、灾害管理、城市规划等资源监测中发挥重要作用[11 -12 ] .然而,现有的VQA研究多集中于自然图像,而自然图像由于存在景深和虚化的关系,人们往往只关注图像中的显著性目标,忽略全局性场景.但在遥感影像中,所有目标均在同一焦平面,因此对于全局场景的理解和局部目标的识别同样重要.这种从全局到局部的尺度变化令传统VQA模型难以直接迁移至遥感图像中,为遥感VQA研究带来了新的挑战.文中从遥感VQA的实际需求出发,解决遥感影像VQA中的尺度变化问题,设计多尺度遥感影像VQA的数据集和模型. ...
RSVQA: Visual question answering for remote sensing data
2
2020
... 近年来,视觉问答在遥感领域也有少量研究成果[13 -16 ] .2020年Lobry等[13 ] 采用自动生成标签的方式首次构造了一个应用于遥感VQA的数据集并命名为RSVQA,RSVQA中的图像来自于OpenStreetMAp数据和Sentinel-2数据,问答设计利用原始图像提取图像特征以及属性,根据问题模板选择生成正确答案,在问题设计上仅有5类对象属性问题(如:计数,比较,存在性,面积,城市或郊区)等.2021年Maryam等[14 ] 提出了一个命名为FloodNet的数据集,该数据集为洪水过后的高分辨率航空遥感影像,分别设计了遥感图像分类、语义分割和视觉问答三大性能,其中VQA部分数据集问答模式有三种类型,关于计数、关于整张图像的情况以及yes/no 类型问答.Yuan等[15 ] 提出了一组适用于遥感变化检测的遥感VQA数据集CDVQA,该数据集以现有的变化检测数据集为基础,自动生成CDVQA数据集,CDVQA问答类型针对区域变化情况进行提问. ...
... [13 ]采用自动生成标签的方式首次构造了一个应用于遥感VQA的数据集并命名为RSVQA,RSVQA中的图像来自于OpenStreetMAp数据和Sentinel-2数据,问答设计利用原始图像提取图像特征以及属性,根据问题模板选择生成正确答案,在问题设计上仅有5类对象属性问题(如:计数,比较,存在性,面积,城市或郊区)等.2021年Maryam等[14 ] 提出了一个命名为FloodNet的数据集,该数据集为洪水过后的高分辨率航空遥感影像,分别设计了遥感图像分类、语义分割和视觉问答三大性能,其中VQA部分数据集问答模式有三种类型,关于计数、关于整张图像的情况以及yes/no 类型问答.Yuan等[15 ] 提出了一组适用于遥感变化检测的遥感VQA数据集CDVQA,该数据集以现有的变化检测数据集为基础,自动生成CDVQA数据集,CDVQA问答类型针对区域变化情况进行提问. ...
Floodnet: A high resolution aerial imagery dataset for post flood scene understanding
1
2021
... 近年来,视觉问答在遥感领域也有少量研究成果[13 -16 ] .2020年Lobry等[13 ] 采用自动生成标签的方式首次构造了一个应用于遥感VQA的数据集并命名为RSVQA,RSVQA中的图像来自于OpenStreetMAp数据和Sentinel-2数据,问答设计利用原始图像提取图像特征以及属性,根据问题模板选择生成正确答案,在问题设计上仅有5类对象属性问题(如:计数,比较,存在性,面积,城市或郊区)等.2021年Maryam等[14 ] 提出了一个命名为FloodNet的数据集,该数据集为洪水过后的高分辨率航空遥感影像,分别设计了遥感图像分类、语义分割和视觉问答三大性能,其中VQA部分数据集问答模式有三种类型,关于计数、关于整张图像的情况以及yes/no 类型问答.Yuan等[15 ] 提出了一组适用于遥感变化检测的遥感VQA数据集CDVQA,该数据集以现有的变化检测数据集为基础,自动生成CDVQA数据集,CDVQA问答类型针对区域变化情况进行提问. ...
Change detection meets visual question answering
1
2022
... 近年来,视觉问答在遥感领域也有少量研究成果[13 -16 ] .2020年Lobry等[13 ] 采用自动生成标签的方式首次构造了一个应用于遥感VQA的数据集并命名为RSVQA,RSVQA中的图像来自于OpenStreetMAp数据和Sentinel-2数据,问答设计利用原始图像提取图像特征以及属性,根据问题模板选择生成正确答案,在问题设计上仅有5类对象属性问题(如:计数,比较,存在性,面积,城市或郊区)等.2021年Maryam等[14 ] 提出了一个命名为FloodNet的数据集,该数据集为洪水过后的高分辨率航空遥感影像,分别设计了遥感图像分类、语义分割和视觉问答三大性能,其中VQA部分数据集问答模式有三种类型,关于计数、关于整张图像的情况以及yes/no 类型问答.Yuan等[15 ] 提出了一组适用于遥感变化检测的遥感VQA数据集CDVQA,该数据集以现有的变化检测数据集为基础,自动生成CDVQA数据集,CDVQA问答类型针对区域变化情况进行提问. ...
Capturing Global and Local Information in Remote Sensing Visual Question Answering
1
2022
... 近年来,视觉问答在遥感领域也有少量研究成果[13 -16 ] .2020年Lobry等[13 ] 采用自动生成标签的方式首次构造了一个应用于遥感VQA的数据集并命名为RSVQA,RSVQA中的图像来自于OpenStreetMAp数据和Sentinel-2数据,问答设计利用原始图像提取图像特征以及属性,根据问题模板选择生成正确答案,在问题设计上仅有5类对象属性问题(如:计数,比较,存在性,面积,城市或郊区)等.2021年Maryam等[14 ] 提出了一个命名为FloodNet的数据集,该数据集为洪水过后的高分辨率航空遥感影像,分别设计了遥感图像分类、语义分割和视觉问答三大性能,其中VQA部分数据集问答模式有三种类型,关于计数、关于整张图像的情况以及yes/no 类型问答.Yuan等[15 ] 提出了一组适用于遥感变化检测的遥感VQA数据集CDVQA,该数据集以现有的变化检测数据集为基础,自动生成CDVQA数据集,CDVQA问答类型针对区域变化情况进行提问. ...
AID: A benchmark data set for performance evaluation of aerial scene classification
1
2017
... MRS-VQA数据集中的图像来源于遥感分类影像AID数据集[17 ] ,该数据集包含30个不同的场景,包括机场、裸地、棒球场、海滩、桥梁、行政中心、教堂、商业区、密集住宅、沙漠、农田、森林、工业区、草坪、中型住宅、山地、公园、停车场、游乐场、池塘、港口、火车站、度假村、河流、学校、稀疏住宅、广场、体育场、蓄水池、高架桥.每个场景约230张大小为600×600像素的图像,图像分辨率在0.5 m~8 m之间,本文从每个场景中随机选取100张图像作为本文的图像数据源,共计3 000张影像. ...
Stacked attention networks for image question answering
1
2016
... 本文提出一种多尺度遥感视觉问答(MRS-VQA)模型,该模型结合了图像模块中的多尺度特征,以解决图像中尺度变化的影响.模型结构如图3 所示.图像模块使用卷积神经网(CNN)提取图像特征,并用循环神经网络(RNN)提取文本特征,在融合模块使用注意力机制,答案预测模块视为一个分类过程[18 -21 ] ,最后使用s o f t m a x
A focused dynamic attention model for visual question answering
0
2016
attend and answer: Exploring question-guided spatial attention for visual question answering
0
2016
Where to look: Focus regions for visual question answering
1
2016
... 本文提出一种多尺度遥感视觉问答(MRS-VQA)模型,该模型结合了图像模块中的多尺度特征,以解决图像中尺度变化的影响.模型结构如图3 所示.图像模块使用卷积神经网(CNN)提取图像特征,并用循环神经网络(RNN)提取文本特征,在融合模块使用注意力机制,答案预测模块视为一个分类过程[18 -21 ] ,最后使用s o f t m a x
Very deep convolutional networks for large-scale image recognition
1
2014
... 图像模块:图像模块用CNN获取图像的初始特征.CNN已经成为一种功能强大的图像特征提取器,VGG-16[22 ] 作为CNN中最经典的图像特征提取器之一,其强大的特征提取能力能够在各种任务中表现出色的性能[23 -25 ] .因此,为了解决遥感图像中目标的多样性和尺寸差异问题,本文以VGG-16网络主干为基准,提取多尺度特征图.VGG-16网络中有5个尺寸不同的ConvBlock模块,前两个模块中每个模块有两个卷积层,后三个模块中每个模块有三个卷积层,我们选择后三个模块中的最后一个卷积提取的特征图,因前两个模块总共只有四层卷积,网络层数较浅,学习到的有效信息较少且数据冗余较大,因此选择的是后三个模块,得到三个具有不同尺度的特征图.首先输入大小为448×448像素大小的图像,模型使用VGG-16中的第三(ConvBlock3大尺度)、第四(ConvBlock4中尺度)和第五(ConvBlock4小尺度)块中的最后一层卷积提取图像特征,特征图大小分别为112×112×256、56×56×512、28×28×512像素,获得3个具有最大尺度差异组合的不同尺度特征,然后将这三个不同尺度的特征合并为一个融合特征,并以张量形式输出.这样既能充分利用原始图像的语义信息也能够避免过多特征融合造成的数据冗余.该过程可以用公式(1) 描述: ...
ScratchDet: Training single-shot object detectors from scratch
1
2019
... 图像模块:图像模块用CNN获取图像的初始特征.CNN已经成为一种功能强大的图像特征提取器,VGG-16[22 ] 作为CNN中最经典的图像特征提取器之一,其强大的特征提取能力能够在各种任务中表现出色的性能[23 -25 ] .因此,为了解决遥感图像中目标的多样性和尺寸差异问题,本文以VGG-16网络主干为基准,提取多尺度特征图.VGG-16网络中有5个尺寸不同的ConvBlock模块,前两个模块中每个模块有两个卷积层,后三个模块中每个模块有三个卷积层,我们选择后三个模块中的最后一个卷积提取的特征图,因前两个模块总共只有四层卷积,网络层数较浅,学习到的有效信息较少且数据冗余较大,因此选择的是后三个模块,得到三个具有不同尺度的特征图.首先输入大小为448×448像素大小的图像,模型使用VGG-16中的第三(ConvBlock3大尺度)、第四(ConvBlock4中尺度)和第五(ConvBlock4小尺度)块中的最后一层卷积提取图像特征,特征图大小分别为112×112×256、56×56×512、28×28×512像素,获得3个具有最大尺度差异组合的不同尺度特征,然后将这三个不同尺度的特征合并为一个融合特征,并以张量形式输出.这样既能充分利用原始图像的语义信息也能够避免过多特征融合造成的数据冗余.该过程可以用公式(1) 描述: ...
Towards optimal structured cnn pruning via generative adversarial learning
0
2019
A simple pooling-based design for real-time salient object detection
1
2019
... 图像模块:图像模块用CNN获取图像的初始特征.CNN已经成为一种功能强大的图像特征提取器,VGG-16[22 ] 作为CNN中最经典的图像特征提取器之一,其强大的特征提取能力能够在各种任务中表现出色的性能[23 -25 ] .因此,为了解决遥感图像中目标的多样性和尺寸差异问题,本文以VGG-16网络主干为基准,提取多尺度特征图.VGG-16网络中有5个尺寸不同的ConvBlock模块,前两个模块中每个模块有两个卷积层,后三个模块中每个模块有三个卷积层,我们选择后三个模块中的最后一个卷积提取的特征图,因前两个模块总共只有四层卷积,网络层数较浅,学习到的有效信息较少且数据冗余较大,因此选择的是后三个模块,得到三个具有不同尺度的特征图.首先输入大小为448×448像素大小的图像,模型使用VGG-16中的第三(ConvBlock3大尺度)、第四(ConvBlock4中尺度)和第五(ConvBlock4小尺度)块中的最后一层卷积提取图像特征,特征图大小分别为112×112×256、56×56×512、28×28×512像素,获得3个具有最大尺度差异组合的不同尺度特征,然后将这三个不同尺度的特征合并为一个融合特征,并以张量形式输出.这样既能充分利用原始图像的语义信息也能够避免过多特征融合造成的数据冗余.该过程可以用公式(1) 描述: ...
Long short-term memory
1
1997
... 问题模块:为了理解和表示问题的语义信息,本模块使用两层长短记忆网络(LSTM)[26 ] 来处理输入的问题Q . 首先,将输入的问题Q = [ q 1 , q 2 , . . . , q n ] W [ ⋅ ] q n Q 公式(3) 获取输入的问题特征. ...
Deep residual learning for image recognition
1
2016
... 本实验中,为了验证MRS-VQA数据集的有效性,将MRS-VQA数据集分别在我们的模型MRS-VQA与RSVQA模型上进行训练和验证.RSVQA模型使用ResNet-152[27 ] 提取图像特征,文本模块使用skip-thoughts[28 ] ,特征融合模块采用简单向量点乘方式,答案预测以分类的方式输出答案. ...
Skip-thought vectors
1
2015
... 本实验中,为了验证MRS-VQA数据集的有效性,将MRS-VQA数据集分别在我们的模型MRS-VQA与RSVQA模型上进行训练和验证.RSVQA模型使用ResNet-152[27 ] 提取图像特征,文本模块使用skip-thoughts[28 ] ,特征融合模块采用简单向量点乘方式,答案预测以分类的方式输出答案. ...


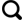





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}