

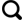


1 引 言
近10年,随着机器视觉领域的快速发展,涌现出大量基于机器视觉的目标自动检测算法,已在自然图像领域取得较好的应用效果,其中由Felzenszwalb提出的DPM(Defomable Parts Model)算法,连续获得VOC(Visual Object Class)大赛2007~2009年度的检测冠军。随着卷积神经网络被成功应用到场景目标分类,深度学习技术在目标检测方面也取得了不错的效果,与传统依赖先验知识的特征提取算法不同,基于深度学习的目标检测对几何变换、形变、光照具有一定程度的不变性,并且可在训练数据驱动下自适应地构建特征描述,具有更高的灵敏性和泛化能力[4]。“深度学习”概念于2006年由加拿大的Hinton教授提出[5],2012年,Hinton教授和他的学生Alex等[6]将深度卷积神经网络应用于在ImageNet挑战赛上,Top-5错误率比上一年的冠军下降了10个百分点,而且远远超过当年的第二名,引起了学术界和工业界的广泛关注。目前深度学习在机器视觉领域应用越来越广泛,网络层数呈现越来越多的趋势。微软亚洲研究院团队提出的深达152层的深度残差网络ResNet[7]在ILSVRC2015 (ImageNet Large scale Visual Recognition Competition 2015)年的计算机视觉挑战赛中获得图像检测、图像分类和图像定位3个项目的冠军,图像分类的错误率为3.57%,甚至超过了人类的识别精度。相对于传统的目标检测算法,基于深度学习的目标检测算法流程更精简、精度更高。常见的基于深度学习目标检测算法包括两类,一类是基于候选区域(Region Proposal)的深度学习目标检测算法,如R-CNN[8]、Fast R-CNN、Faster R-CNN[9]等,另一类是基于回归方法的深度学习目标检测算法,如YOLO[10]、SSD[11]。
在遥感图像的目标检测方面,由于遥感图像不同于相机拍摄的自然图像,遥感图像易受噪声、拍摄角度、时间和气候等诸多因素的影响,并且目标尺寸较小。目前,基于候选区域的深度学习目标检测算法在遥感领域应用较广泛,戴陈卡等[12]基于Faster R-CNN以及多部件结合对机场场面静态飞机进行目标检测,对不同姿态、不同场景下的飞机目标检测准确率达到90%以上。王万国等[13]基于候选区域的深度学习目标检测算法结合无人机巡检图像对电力小部件进行识别,达到每张近80 ms的识别速度和92.7%的准确率。胡炎等[14]基于深度卷积神经网络结合SAR影像对海上舰船目标进行检测,并对4种不同海洋杂波环境的宽幅SAR图像进行测试,均得到了较好的检测结果。
基于候选区域的深度学习目标检测算法是目前较为主流的目标检测算法,因此本文采用基于候选区域的深度学习目标检测方法,综合对比了Faster R-CNN和R-FCN两种效果较好的算法,对遥感影像上的油罐目标进行了检测,并提出了通过增加锚点尺度的方法来提高油罐检测精度,以便为深度学习技术在工业区监测及自然资源监管等方面提供了技术参考。
2 基于候选区域的深度学习目标检测算法
基于深度学习的目标检测方法,是在深度卷积神经网络的基础上,增加目标位置判断的网络,在输出目标类别的同时,输出目标空间位置和尺寸,由于油罐目标在遥感影像中的尺寸较小,本文采用基于候选区域的深度学习目标检测算法来对油罐目标进行检测,其中Faster R-CNN和R-FCN是检测效果较好的两种模型。
2.1 Faster R-CNN目标检测原理
2014年由微软研究院的Ross B Girshick提出,采用基于建议区域(Region Proposal RP)和卷积神经网络(CNN)代替传统的滑动窗口和手工设计特征,形成了R-CNN框架,经过几年的发展建立的Faster R-CNN[9],在速度和精度方面又有了一定提升。
Faster R-CNN网络结构包含3部分:特征提取网络、区域候选网络和分类回归网络,前两部分都是卷积神经网络,而且在训练和测试的过程中都有卷积共享,从而提高了效率。
图1
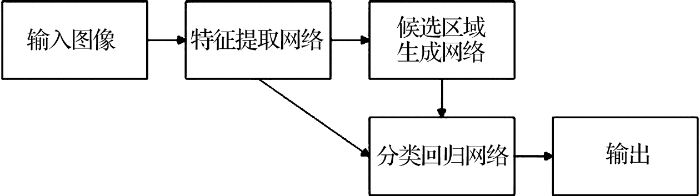
图1
Faster R-CNN算法网络结构
Fig.1
The network structure of the Faster R-CNN framework
2.1.1 特征提取网络
在Faster R-CNN算法网络中,训练样本的数量是影响网络性能的决定因素,充分训练一般要求上百万数量级的图片。因此在深度学习中,研究人员通过迁移学习的方法来提高网络性能,即把在海量数据中训练好的网络应用到自己的数据中,然后微调该网络以达到快速收敛的目标。Jason等[16]通过实验对比得出结论:微调一个预训练好的卷积神经网络,比从头开始训练网络具有更好的分类精度和更快的收敛速度。底层网络学习到的图像特征具有很好的泛化能力,对于不同的数据集都有很好的表示。
2.1.2 候选区域生成网络(RPN)
在Faster R-CNN网络中,候选区域网络是一个卷积神经网络,该网络以特征提取网络输出的特征图作为输入,输出多种尺度和宽高比的矩形候选区域。候选区域网络首先利用一个卷积核在特征图上进行卷积操作生成特征向量,然后将每个特征向量输入到两个全连接层中,然后输出候选区域的分数和修正参数,每个滑动窗口位置定义了9个候选区域,每个候选区域对应4个修正参数、2个分数,分别代表该候选区域内包含和不包含待测目标的可能性。网络结构如图2所示。
图2
2.1.3 分类回归网络
图3

因为候选区域网络输出的候选区域形状、大小各异,所以不同候选区域所包含的特征向量维度也各不相同。而全连接层对输入特征向量维度有固定限制,所有输入特征向量维度必须相同,因此分类回归网络首先使用一个ROIpooling层将候选区域所包含的特征池化成大小、形状相同的特征图,然后用两个全连接层对特征图进行特征映射,然后使用全连接层cls_score、bbox_pred输出各个类别的分数和修正参数,并使用Softmax层将分数归一化,得到候选区域各个类别的置信度。
2.2 R-FCN原理
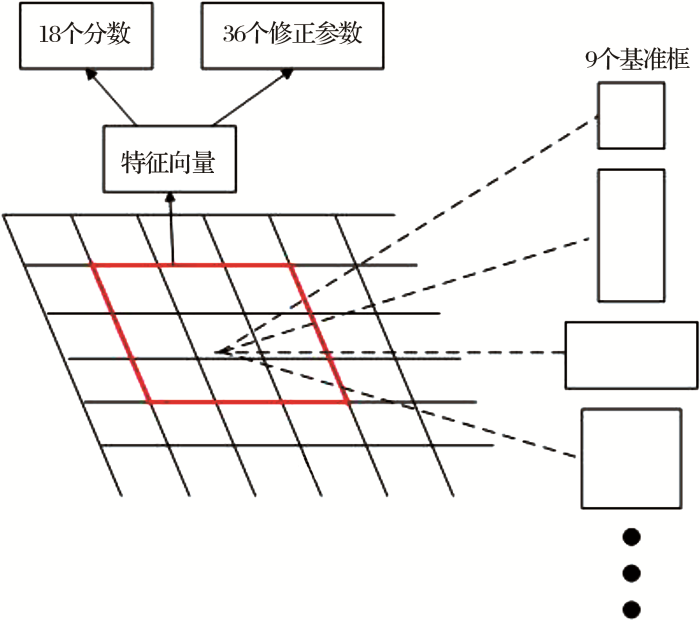
由于Faster R-CNN在卷积层之后连接的是感兴趣区域池化层,网络结构的平移不变性被削弱,因此Dai等[19]在Faster R-CNN的基础上提出了R-FCN模型,采用专门的卷积层构建位置敏感分数图代替Faster R-CNN的感兴趣区域池化层,使网络具备更好的平移不变性,该方法已经在ImageNet挑战赛和COCO目标检测任务中取得较好的效果。
在具体实现中,首先输入一张图片,经过一个参数共享的全卷积神经网络,得到特征映射图,然后将特征映射图输出给区域建议网络(RPN)对全图的前后景目标进行搜索和筛选,以确定候选框。得到一系列的候选窗口后,特征图经过一个专门的卷积层,在整幅图像上为每类生成k2个位置敏感分数图,用于描述对应位置的空间网格;每个位置敏感图有C+1个通道输出(C类待检测目标和1个背景)[20],R-FCN最后用位置敏感的ROI池化层来管理这些得分图的信息,并且这一层是没有任何权重的。如果一个大小为w×h的候选框将被划分为k×k个子区域,每个子区域大小为w×h/k2,因此对于任意一个子区域bin(i,j),0≤i,j≤k-1,位置敏感的池化操作如公式(1)所示:
图4
3 油罐目标检测试验与分析
3.1 训练样本集制作
常规的目标检测数据集有很多,但基于常规数据集训练出来的网络在遥感影像上效果并不好,主要是因为遥感影像存在尺度多样、视角特殊、小目标问题等特殊性。因此对于遥感影像的目标检测工作,常规的数据集往往难以训练出理想的目标检测器,需要专门的遥感影像样本集来训练网络。目前常用的遥感影像数据集有:DOTA、NWPU VHR-10、UC_Merced等,在本文实验中,主要用到UC_Merced、RSOD、AID、NWPU-RESISC45共4种遥感数据集,还辅助使用了部分高分二号(GF2)获取的遥感数据。本文实验中制作了1 300张油罐样本图片,总共包含约2.5万个不同尺寸的油罐目标,使用其中60%的图片作为训练和验证,其余40%作为测试。训练样本样例如图5所示,采用LabelImg标注工具人工标注其中的油罐样本外边框和类别。
图5

3.2 卷积网络特征
深度卷积网络学习到的特征具有辨别性,背景部位的激活度很少,通过可视化过程结果,可以看出提取到的特征忽略了背景,提取到了目标中的关键信息。图6显示的是ZF模型各个卷积层学习到的特征,为了显示清晰,将灰度特征图用彩色来显示,从图6可以看出,随着卷积网络层的加深,提取到的特征越来越丰富,conv1、conv2学习到一些基本的特征比如颜色、边缘等底层特征;conv3学习到一些纹理特征;conv4、conv5则是学习到一些具有关键辨别性的特征。上述各卷积层提取的特征都不是利用人工工程来设计的,而是使用一种通用的学习过程从数据中学到的,这就是深度卷积神经网络的关键优势即不需要手工设计特征提取器,通过通用学习过程而得到良好的特征;深度卷积神经神经网络把原始数据通过一些简单的但是非线性的模型转变成为更高层次的,更加抽象的表达,通过足够多的转换的组合,非常复杂的函数也可以被学习,因此能够发现大数据中的复杂结构,具有更高的灵敏性和泛化能力[22]。在油罐目标的遥感监测中,由于光照、传感器成像质量及油罐材料、结构、位置等因素的影响,部分油罐目标特征不明显,采用传统的手工设计特征的方法提取油罐目标,往往存在适用范围有限、泛化能力较弱的问题,基于深度卷积神经网络对油罐目标进行目标检测,能根据不同来源的训练数据集自适应的构建特征描述,进而有效地提取油罐的目标特征,同时削弱不相关因素,具有更高的泛化能力和更高的效率。
图6

图6
ZF模型各个卷积层提取到的特征
Fig.6
The extracted features of convolution layer from ZF model
3.3 实验结果及分析
在本文实验中,Faster R-CNN算法利用典型的ZF[23]和VGG16[24]网络,训练和微调网络的各项参数,R-FCN算法则利用深度残差网络ResNet-50[7]来训练网络。ZF模型网络包括5个卷积层和3个全连接层,该网络是ILSVRC2013(ImageNet Large scale Visual Recognition Competition 2013)冠军。VGG16是由牛津视觉几何组开发的卷积神经网络,并赢得了ILSVRC2014的冠军,该网络有13个卷积层,3个全连接层。ResNet-50[7]在2015年横空出世,并获得当年ILSVRC2015冠军,该网络利用残差学习单元减少了参数量,解决了在训练很深网络时会遇到的梯度消失和梯度爆炸的问题,使得模型深度得以进一步加深(49个卷积层和1个全连接层),同时错误率也大大降低。在本文实验中,待检测目标只有一个类别即油罐,所以需要根据待检测目标类别数修改上述模型中的参数。本文使用Caffe框架实现卷积神经网络模型,所有试验均基于同一台GPU服务器(显卡:NVIDIA GTX1080TI)进行测试。
3.3.1 目标检测结果
分别对3种模型进行训练测试,每种模型分别采用交替优化和端到端两种训练方式进行训练,交替优化方式即训练两个网络,一个是RPN,一个是Fast R-CNN,一共有两个阶段,每个阶段各训练一次RPN和Fast R-CNN;端到端训练采用一次性训练的方式完成模型权重的更新。为了比较各种模型和训练方式的效率和精度,采用准确率(mAP)和召回率(recall)来评价目标检测的精度,其中,召回率=正确识别油罐的数量/测试图像中油罐的总数量,准确率=正确识别油罐的数量/模型识别出的所有油罐数量,结果如表1所示。
表1 两种训练方式油罐检测结果
Table 1
| 网络 | 准确率 | 召回率 | 时间/h | |||
|---|---|---|---|---|---|---|
| 端到端 | 交替 优化 | 端到端 | 交替 优化 | 端到端 | 交替优化 | |
| ZF | 0.619 | 0.610 | 0.622 | 0.618 | 3 | 5 |
| VGG16 | 0.618 | 0.612 | 0.664 | 0.669 | 7.5 | 14 |
| ResNet-50 | 0.626 | 0.600 | 0.695 | 0.693 | 4 | 13 |
从表中结果可看出,对于Faster R-CNN而言,VGG16的精度比ZF略高,同时由于VGG16网络更深,训练时间更长;R-FCN的ResNet-50的检测精度略高于ZF和VGG16,但是由于残差网络特殊的网络结构,训练时间比VGG16短。
3种网络通过交替优化训练和端到端训练两种方式得到的结果精度相差不大,但是交替优化训练花费的训练时间明显增多,这是因为:在交替训练中,RPN训练结束后,会有一个RPN生成的过程,这时会生成所有训练图片的候选区域框,耗费大量的时间;而使用端到端训练方式,一次训练一张图片,RPN阶段产生一张图片的候选区域框,然后送入Fast R-CNN训练,因此端到端的训练方式更省时省内存。
3.3.2 改进锚点参数的效果
Faster R-CNN和R-FCN网络中,原始的数据集是VOC数据集,图片大小集中在500×375左右,每张图片约2~5个目标,而本文待检测目标是遥感图像中的油罐,且样本图片大小在300×300左右,每张样本图片中平均约20个油罐目标,因此考虑对用于检测目标的候选框尺度进行调整。
2.1.3小节提到区域建议网络(RPN),RPN以特征提取网络输出的特征图作为输入,输出一批矩形区域候选框,每个区域对应一个目标存在的概率分数和位置信息。在最后一个卷积层的特征图上每个像素点称为锚点(anchor),每个锚点都是以滑动窗口的中心为中心,大小是由尺度和长宽比两个元素构成。在自然图像的目标检测中,Faster R-CNN和R-FCN网络中,锚点的默认设置是采用了1282、2562、51223种面积尺度,以及1∶1、1∶2、 2∶1等3种长宽比例,每个锚点可以对应原始图像上的九个候选框。针对油罐这种小目标的检测,可以通过修改锚点的对应的面积大小和长宽比例,来调整目标检测候选框的尺度,提高对油罐目标的检测精度。本文对锚点的面积尺度和长宽比例均进行了修改,长宽比例增加为1∶4、1∶2、3∶4、1∶1、2∶1等5种,面积尺度增加为22、42、62、82、102、122、142、162、322、642、1282、2562、5122共13种,修改后每个锚点可以产生65个候选框。实验结果如表2所示。
表2 不同模型修改锚点大小对油罐检测的影响
Table 2
| 网络 | 准确率(mAp) | 召回率(recall) | 时间/h | |||
|---|---|---|---|---|---|---|
| 修改前 | 修改后 | 修改前 | 修改后 | 修改前 | 修改后 | |
| ZF | 0.619 | 0.712 | 0.622 | 0.728 | 3 | 3 |
| VGG16 | 0.618 | 0.714 | 0.664 | 0.764 | 7.2 | 7.5 |
| ResNet-50 | 0.626 | 0.716 | 0.695 | 0.795 | 4 | 4 |
从表2可以看出,对锚点对应的面积尺度和长宽比例进行调整后,上述3个模型识别油罐的准确率和召回率均有明显的提升,且增加锚点的数量,训练耗费的时间增加的并不明显。实验证明,针对不同的数据集,不同大小的待检测目标,通过修改锚点大小和数量,即丰富了候选框类型和数量,进而对提升模型识别精度有较好的效果,特别是遥感影像中的小目标识别,修改锚点的大小和数量是很有必要的。
为直观展示三种模型的检测效果,随机选取部分检测效果图,如图7所示。从图中可看出,3个模型对油罐的识别效果总体来说相差不大,ZF模型有将非油罐区域误识别为油罐的情况,ResNet-50模型精度虽然比其他两种模型高,但是对图像边缘上的目标检测效果不如ZF和VGG16。综合3种模型的检测效果可以看出,基于深度学习的高分辨率遥感影像上油罐目标检测取得了较好的效果,能够通过查找油罐目标,找到工业园区疑似区域,分析该工业园区对生态环境的影响。
图7

4 结 语
本文探讨了基于深度卷积神经网络的在高分辨率遥感影像目标检测中的有效性,采用Faster R-CNN和R-FCN算法对遥感图像油罐进行检测,并提出针对遥感图像小目标的检测,通过增加锚点的方法,提升检测精度,实现了对遥感影像上油罐目标的检测,召回率可接近80%,为深度学习在特定目标检测的应用提供了实例和新的思路。
目前,基于深度学习的目标检测算法还处于初步阶段,虽然在深度学习推动下,目标检测的准确率已经取得了跨越式的提高,但是基于深度学习的目标检测还有很大的提高空间,特别是应用于遥感图像目标检测领域。基于深度学习的目标检测在不断进步和发展,本文只是进行了初步的研究,还有很多问题有待深入研究:
(1)由于本文样本数据是人工标注,难免会有一些主观因素的影响,在实验中,一些面积很小的疑似目标很难被识别出来,这个问题将在后续研究中进一步探索。
(2)不同网络层次能提取不同层次的特征,不同层次的特征对实验结果的贡献程度不同[25]。后续研究中应该进一步理解网络参数的设置和网络结构的设计,针对待检测目标,保留贡献程度较大的网络层参与模型训练过程,改进优化模型,去除冗余信息,提高算法效率。
(3)针对生态红线保护特别是长江经济上游生态环境保护面临的问题和自然资源调查监测的相关要求,在后续的研究中将探索基于深度学习的其他感兴趣目标的识别检测问题,如生态保护区的违规厂房建筑、采矿点等目标的快速检测。
参考文献
An Automatic Oil Tank Detection Algorithm based on Remote Sensing Image
[J].
基于遥感影像的油罐自动检测算法
[J].
Research on Oilcan Segmentation in Remote Sensing Image based on Improved Otsu Algorithm
[J].
基于改进Otsu法的遥感图像油罐目标分割研究
[J].
Oil Tank Extraction from Remote Sensing Images based on Visual Attention Mechanism and Hough Transform
[J].
基于视觉注意机制和Hough变换融合的遥感影像油罐提取
[J].
Vehicle Detection based on Deep Learning in Complex scene
[J].
基于深度学习方法的复杂场景下车辆目标检测
[J].
A Fast Learning Algorithm for Deep Belief Nets
[J].
ImageNet Classification with Deep Convolutional Neural Networks
[C]
Deep Residual Learning for Image Recognition
[C]
Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation
[C]
Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks
[J].
You only Look Once: Unified, Real-time Object Detection
[C]
SSD: Single Shot MultiBox Detector
[M].
Aeroplane Detection in Static Aerodrome based on Faster RCNN and Multi-part Model
[J].
基于Faster RCNN以及多部件结合的机场场面静态飞机检测
[J].
Study on the Electrical Devices Detection in UAV Images based on Region Based Convolutional Neural Networks
[J].
基于RCNN的无人机巡检图像电力小部件识别研究
[J].
Ship Detection based on Faster-RCNN and Multiresolution SAR
[J].
基于Faster-RCNN和多分辨率SAR的海上舰船目标检测
[J].
Research on Object Detection Algorithm Based on Faster R-CNN
[D].
基于Faster R-CNN的目标检测算法的研究
[D].
How Transferable are Features in Deep Neural Networks
[C]
ImageNet Large Scale Visual Recognition Challenge
[J].
Land Cover Classification with Extracted Deep Features of Deep Convolutional Neural Network
[D].
基于深度卷积神经网络自学习特征的地表覆盖分类研究
[D].
R-FCN: Object Detection Via Region-based Fully Convolutional Networks
[M].
Pedestrain Detection Method based on R-FCN
[J].
基于R-FCN的行人检测方法研究
[J].
Object Detection in High Resolution Remote Sensing Images based on Fully Convolution Networks
基于全卷积网络的高分辨遥感影像目标检测
[J].
Visualizing and Understanding Convolutional Networks
[M].
Very Deep Convolutional NetWorks for Large-scale Image Recognition
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}